Google just dropped one of the most practically grounded papers on AI-assisted development I've read this year — "The New SDLC with Vibe Coding" by Addy Osmani, Shubham Saboo, and Sokratis Karakis.
It isn't a hype piece. It's a framework. And if you're building software — or leading teams that do — this paper deserves more than a skim.
In this post, I'll walk you through the six most important ideas from the paper, explain them in plain language, and give you my perspective on what actually matters for production teams.
From Autocomplete to Autonomy — The Evolution Nobody Fully Clocked
Remember when GitHub Copilot launched and the hottest debate was "will it replace developers?"
That was 2021. We were arguing about autocomplete.
The paper maps out a clean evolution timeline that every developer should internalize:
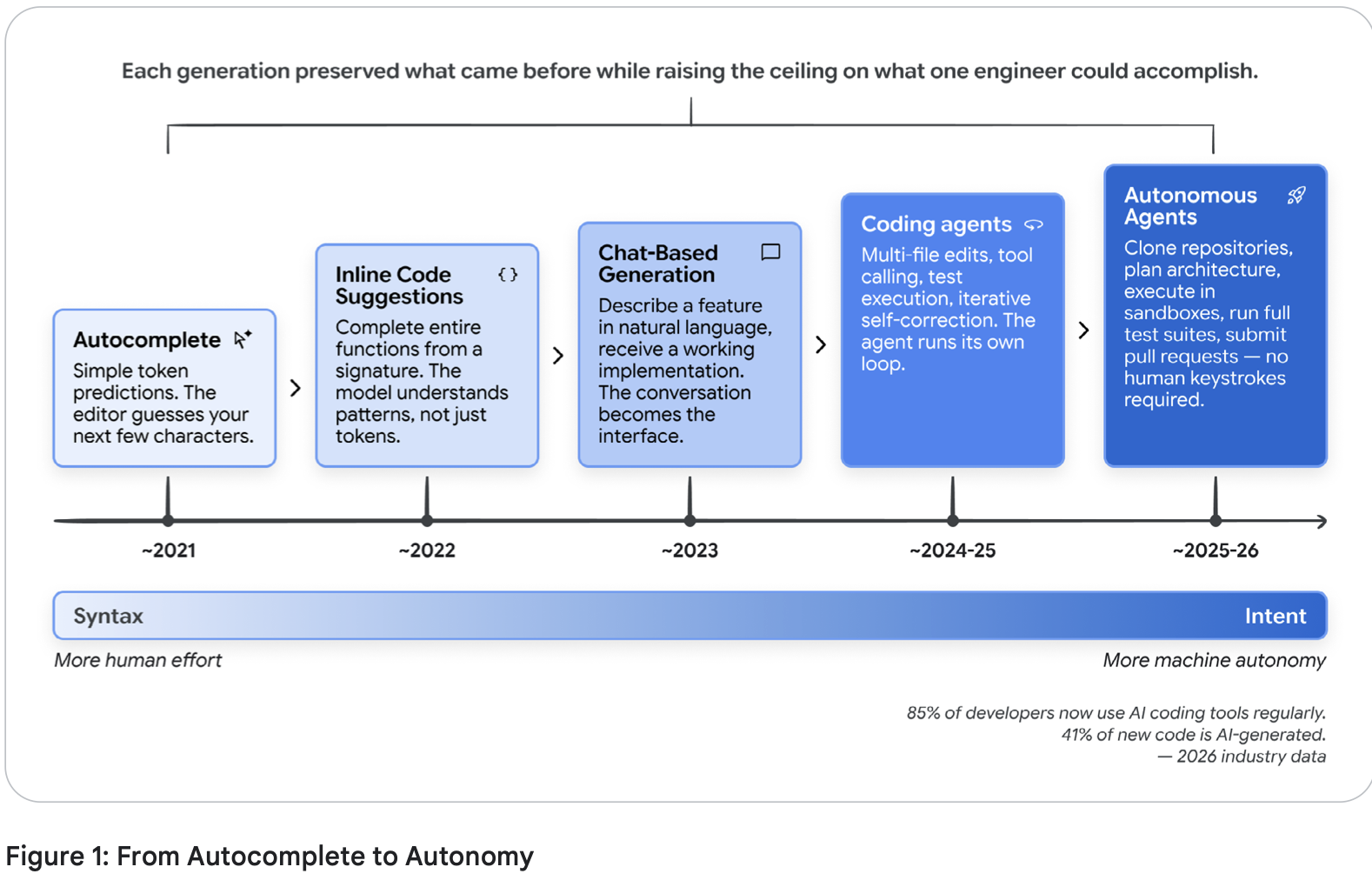
Here's the progression:
Era | What Changed |
~2021 | Autocomplete— simple token prediction, next-line guessing |
~2022 | Inline Code Suggestions— complete entire functions, not just characters |
~2023 | Chat-Based Generation— describe a feature in English, get working code |
~2024-25 | Coding Agents— multi-file edits, test execution, iterative self-correction |
~2025-26 | Autonomous Agents— clone repos, plan architecture, run tests, submit PRs. No human keystrokes required. |
The stat that jumped out at me: as of early 2026, 85% of professional developers regularly use AI Coding Agents, 51% use them daily, and an estimated 41% of all new code is AI-generated.
Think about that. Nearly half the code being pushed today was not typed by a human.
My take as an architect: Each generation here didn't replace the previous one — it raised the ceiling. Autocomplete didn't die; it's still there, inside every agent. What changed is the scope of what one engineer can accomplish in a day. The bottleneck is no longer typing speed or syntax recall. It's specification quality and architectural judgment. That's a fundamentally different skill profile than what most teams were hiring for three years ago.
The Vibe Coding to Agentic Engineering Spectrum — Know Where You Are
"Vibe coding" — Andrej Karpathy coined it in February 2025. The idea: you fully surrender to the AI's output, describe what you want, accept what comes back, and paste errors back into the prompt when things break.
It went viral because it was honest. A lot of us were already doing exactly this.
The problem? The term got applied to everything. A senior engineer carefully reviewing AI output on a well-specified ticket got lumped in with someone who prompt-dumped their way to a broken payment flow.
By early 2026, Karpathy himself stepped back and introduced "agentic engineering" to define the disciplined end of the spectrum.
The paper frames it as a spectrum, not a binary — and that framing is spot-on.
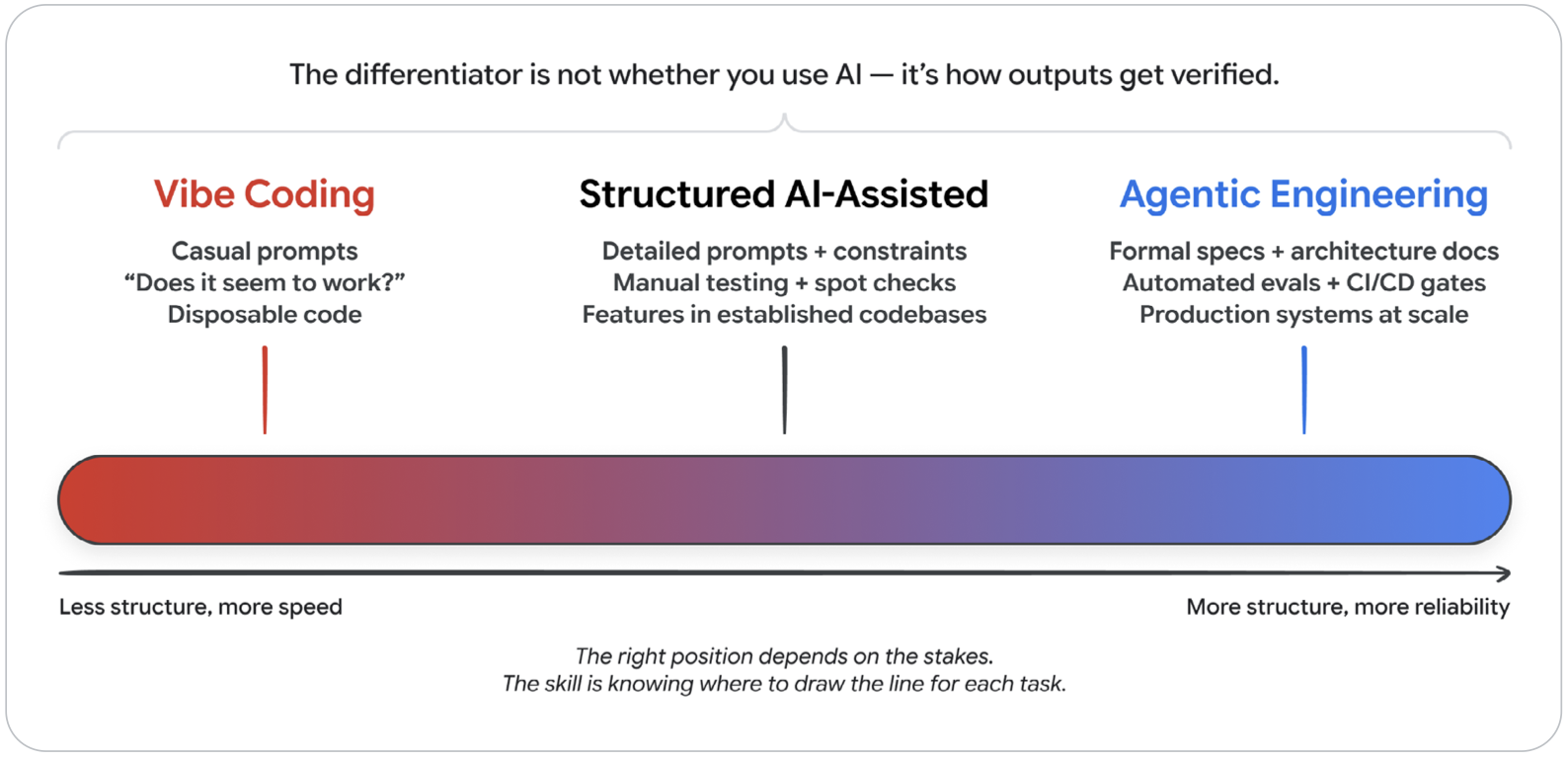
Here's how the two ends look side by side:
Dimension | Vibe Coding | Agentic Engineering |
Intent Specification | Casual natural language prompts | Formal specs, architecture docs, memory files |
Verification | "Does it seem to work?" | Automated test suites, CI/CD gates, LLM judges |
Error Handling | Paste the error back into the prompt | Agents self-diagnose; humans handle architectural issues |
Appropriate Scope | Prototypes, scripts, hackathons | Production systems, team-scale development |
Risk Profile | High — acceptable for disposable code | Low — systematic verification at every stage |
The single biggest differentiator between the two ends? How outputs get verified.
In vibe coding, verification is optional. In agentic engineering, two mechanisms work together:
Tests— verify deterministic behavior: given this input, produce that output.
Evals— verify non-deterministic behavior: did the agent take the right steps, use the right tools, produce quality output?
Without both, you're always vibe coding — no matter how sophisticated your prompts are.
My take as an architect: I've seen teams celebrate "80% productivity gains" on demos that completely fell apart in staging. The issue wasn't the model — it was the absence of an eval harness. The spectrum in this paper is actually a maturity model. Where your team sits on it should be a conscious decision based on the stakes involved. Shipping a weekend prototype? Pure vibe coding is fine. Shipping a financial reconciliation service? You need the full agentic engineering discipline. The skill is knowing where to draw the line — and being honest about which side you're actually on.
Context Engineering — The Real Skill Nobody Is Talking About Enough
Everyone talks about prompt engineering. The paper argues — convincingly — that the real leverage is context engineering.
The insight: the quality of AI-generated code depends less on the cleverness of your prompts and more on the quality of the context you provide.
The paper defines six types of context every agent needs:
Instructions— the agent's role, goals, and what it's forbidden from doing
Knowledge— retrieved documents, architecture diagrams, domain-specific data
Memory— short-term session logs + long-term persistent state (what the project is)
Examples— few-shot behavioral demonstrations and reference patterns
Tools— precise definitions of APIs, scripts, and services the agent can invoke
Guardrails— hard constraints, formatting rules, safety validations
Now here's the architectural decision that separates good teams from great ones — the split between static and dynamic context.
![Fig 3: Context Engineering — Static vs. Dynamic]](https://images.ctfassets.net/driieyo2sul1/1i51MyRWe8X1bTHyaxXUAz/e3ec4513283c69394ad255b698bd5642/ba86adfe-fbee-425e-a03a-8570cc65400f.png)
Static Context — always loaded, every interaction:
System instructions
Rule files (AGENTS.md, CLAUDE.md, GEMINI.md)
Global memory
Core guardrails
Token cost: HIGH — you pay for this on every single call.
Dynamic Context — loaded on demand:
Skill instructions triggered by task matching
Tool results retrieved during execution
Documents fetched from RAG pipelines
Windowed session history
Token cost: LOW — you only pay when the information is actually needed.
The paper introduces a powerful pattern here: Agent Skills — structured, portable packages of procedural knowledge that the agent loads only when the task calls for it. Instead of bloating the system prompt with every possible domain rule, skills let the agent stay a lightweight generalist that flexes into specialist mode on demand.
The result: an agent can carry dozens of specialized capabilities while paying the token cost for only the one it's actively using.
My take as an architect: This is the section I'll be referencing in every architecture review for the next 12 months. Static vs. dynamic context is not a performance optimization — it's a first-class design decision. Teams that treat the AGENTS.md as an afterthought are setting up their agents to drift, repeat mistakes, and burn tokens on irrelevant context. The right mental model: your context files are configuration. Review them in PRs, version them with the codebase, and own them like you own your schema migrations.
Traditional SDLC vs. AI-Driven SDLC — The Same Phases, Different Bottlenecks
The traditional SDLC already went through one major transformation — waterfall to agile. Sprint cycles replaced quarterly releases. CI/CD pipelines replaced manual deployments. Most teams spent a decade making that shift.
AI compresses the cycle again. But — and this is critical — it does so unevenly.
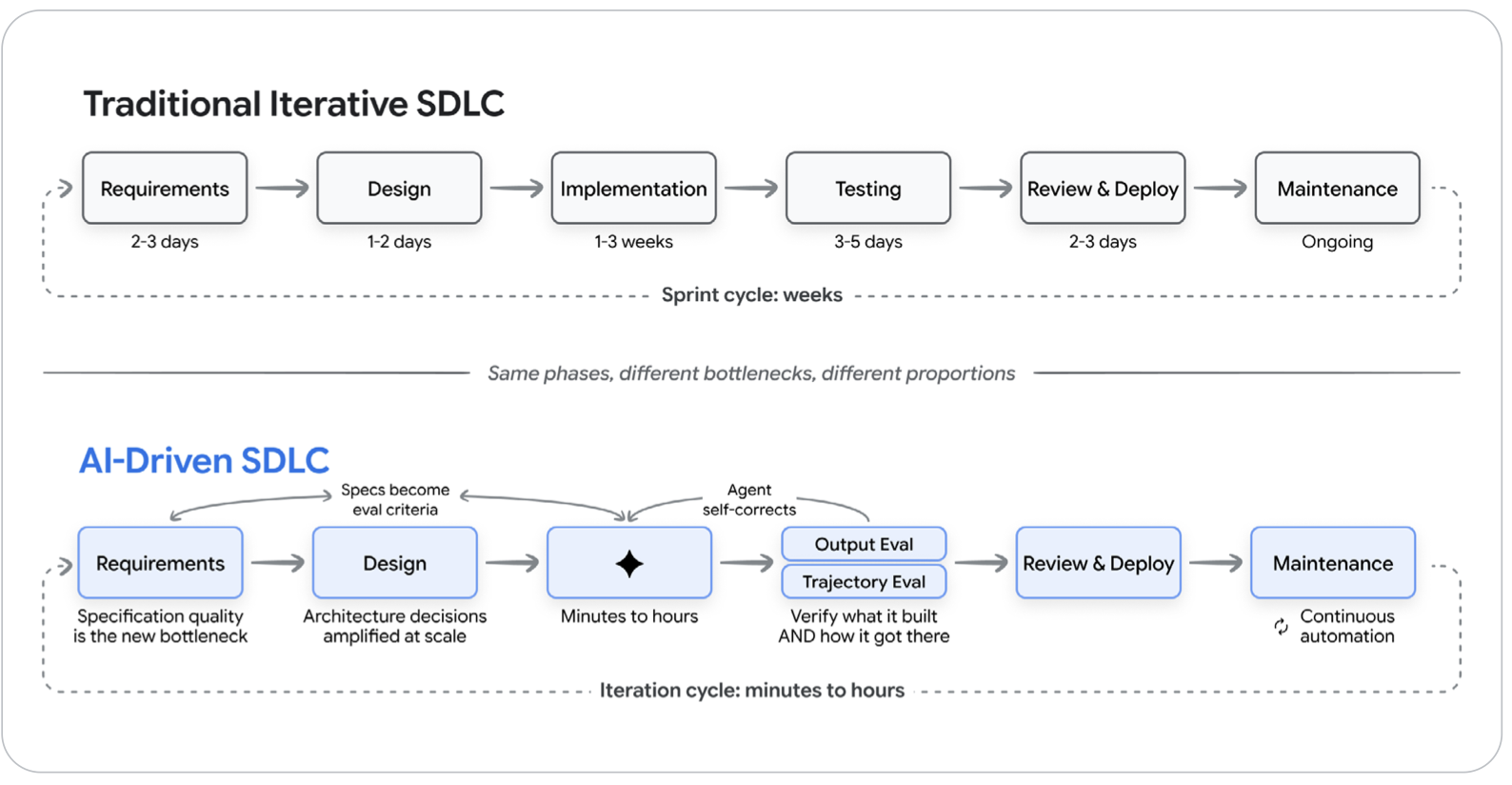
Here's what the paper maps out phase by phase:
Requirements & Planning Before: A document handed between teams, prone to translation errors. After: A conversation between humans and AI that produces specification and initial implementation simultaneously. AI generates user stories from product briefs, catches edge cases humans miss, and produces API schemas from natural language descriptions.
Design & Architecture This phase remains stubbornly human-centric — and for good reason. Architectural trade-offs (consistency vs. availability, complexity vs. flexibility, build vs. buy) depend on business context and long-term strategy that AI cannot fully grasp. AI excels at implementing architectural decisions once they're made, not making them.
Implementation This is where the compression is most dramatic. Implementation that once took 1–3 weeks can now take minutes to hours. Industry surveys report 25–39% productivity improvements. But here's the nuance the paper doesn't shy away from: a METR study found experienced developers using AI assistants actually took 19% longer on certain tasks — because of time spent verifying, debugging, and correcting AI output. AI doesn't eliminate implementation work. It transforms it from writing to reviewing, guiding, and verifying.
Testing & QA The eval flywheel becomes the core feedback loop: evaluate → diagnose → optimize → verify → monitor → repeat. AI generates test cases including edge cases humans wouldn't think of. More importantly, tests and evals become the primary mechanism for communicating intent to AI agents.
Code Review & Deployment AI serves as a first-pass reviewer — flagging bugs, style violations, security vulnerabilities, and performance issues before human reviewers even touch the code. Deployment pipelines are becoming AI-aware, with agents monitoring health and automatically rolling back problematic releases.
Maintenance Perhaps the most underestimated transformation. Legacy codebases that were once "too risky to touch" can now be navigated, refactored, and extended with AI assistance. Technical debt that sat for years because only the original author understood it? Now approachable.
My take as an architect: The traditional SDLC didn't disappear — it's the same phases, just different bottlenecks. Previously, we were bottlenecked on typing speed and implementation time. Now we're bottlenecked on specification quality and verification rigor. Teams that optimize for "faster prompting" are solving the wrong problem. The teams seeing real gains are the ones who invested upfront in clear specs, eval suites, and architectural guardrails — and then let AI handle the implementation.
Harness Engineering — What Actually Surrounds the Model
Here's the mental model that I think most teams get completely wrong.
When an AI agent does something bad, the first instinct is to blame the model. Swap the model. Get a better model.And sometimes that's right.
But more often? The failure traces back to a missing tool, a vague rule, an absent guardrail, or a context window stuffed with noise.
The paper introduces a concept that I think every engineering team needs to internalize: the Harness.
Agent = Model + Harness
The model is the engine. The harness is everything else that makes it functional — the car, the road, and the traffic laws, as the paper puts it.
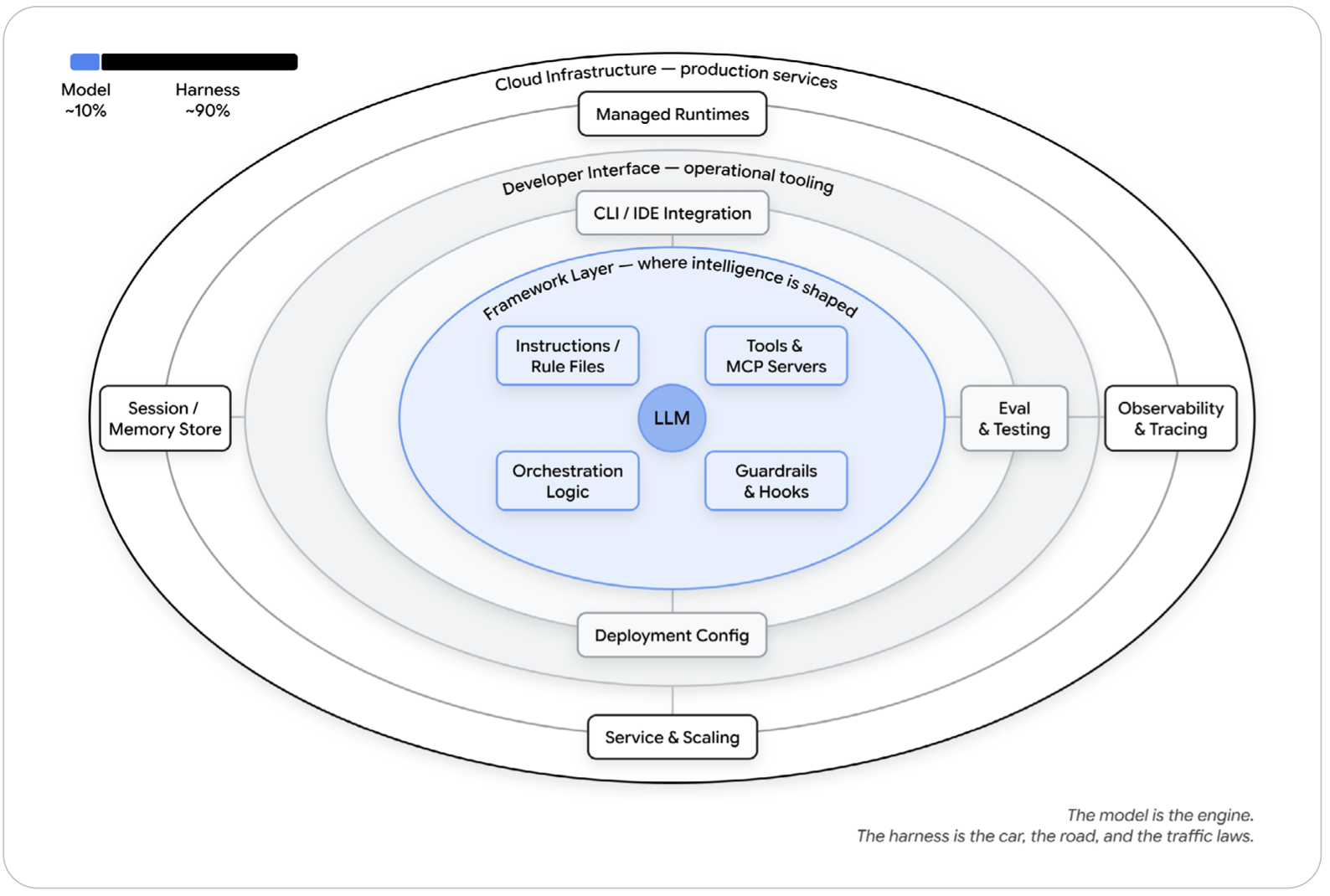
Concretely, the harness includes:
Instructions and Rule Files AGENTS.md, CLAUDE.md, GEMINI.md — the text that defines who the agent is, what it cares about, what it's forbidden from doing. This is where your team's conventions, stack specifics, and hard rules live.
Tools Functions, MCP servers, APIs the agent can call — plus the prose around them that tells the model when and howto use them.
Sandboxes and Execution Environments Where the agent's code actually runs, what it has access to, what it cannot reach. Isolation is not optional for production agents.
Orchestration Logic Sub-agent spawning, model routing, handoffs between specialists, rules that govern when each fires.
Guardrails / Hooks Deterministic code that runs at specific lifecycle points — before a tool call, after a file edit, before a commit. The paper's framing: hooks are for things the agent should never forget but often does.
Observability Logs, traces, evaluations, cost and latency metering. Without observability, you have no way to tell if the agent is performing well or quietly drifting.
The paper backs this up with a compelling benchmark reference: one team moved a coding agent from outside the Top 30 to the Top 5 on Terminal Bench 2.0 by changing only the harness — no model change at all. A separate study raised a coding agent's score by 13.7 points by tweaking only the system prompt, tools, and middleware around a fixed model.
The harness matters more than most teams realize.
My take as an architect: This is the section I'm printing and pinning in our team Confluence. The "harness" framing finally gives us language for something we've been hand-waving around for months. When we onboard a new coding agent, we don't just install it and start chatting. We configure it — rule files, tool access, sandbox scope, hooks for commit hygiene. That configuration is the harness. And it's ours to own, not the model provider's. Most agent failures, when you trace them honestly, are harness configuration failures. Not model failures.
The Economics of AI Development — CapEx vs. OpEx, Reframed
This section of the paper is the one I'd hand to any engineering leader still measuring AI value purely by "lines of code per day."
The real framework: Total Cost of Ownership (TCO), split into CapEx (upfront investment) and OpEx (ongoing running costs).
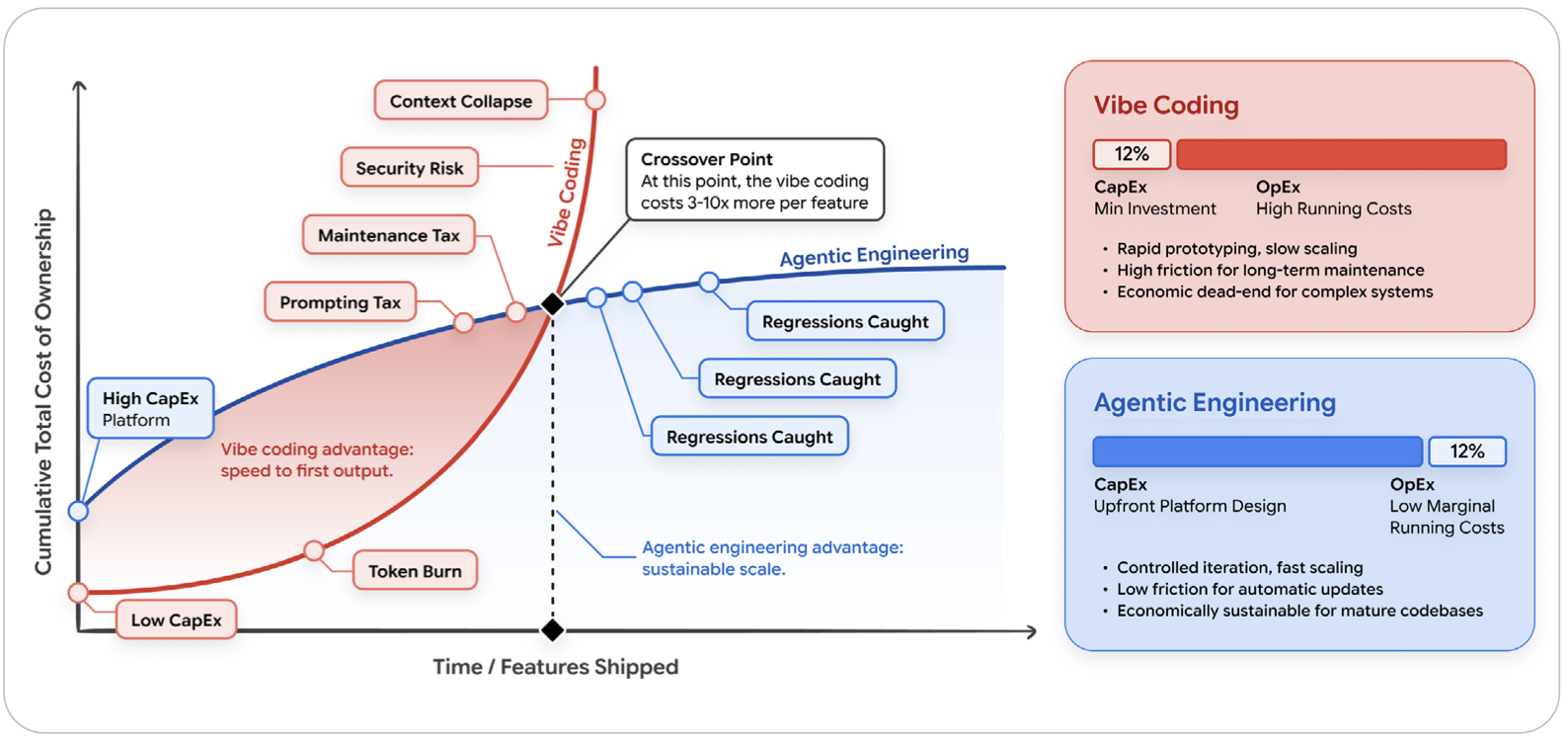
Vibe Coding — Low CapEx, High OpEx
Vibe coding looks cheap on day one. You're paying a monthly subscription, typing some prompts, and shipping features fast. The CapEx is near zero.
But the OpEx compounds silently:
The Token Burn Rate — Dumping massive, unstructured files into a context window and repeatedly asking the model to fix its own unverified mistakes creates an expensive "prompting loop." Low first-pass success rates = high token costs at scale.
The Maintenance Tax — Ad-hoc prompted code often lacks structural consistency. Six months later, when a bug surfaces, engineers spend days reverse-engineering AI-generated spaghetti that no one quite understands.
Security Remediation — Without an automated evaluation harness, rapid code generation means rapid vulnerability generation. The cost of fixing a security flaw in production is exponentially higher than catching it in design.
Agentic Engineering — High CapEx, Low OpEx
Agentic engineering inverts the model. You invest upfront: designing API schemas, building deterministic test suites, structuring the agent's context properly.
That investment is real. But the marginal cost of shipping and maintaining each feature drops dramatically as a result. The AI operates within a governed factory — output is structurally sound, pre-tested, and aligned with standards.
There's also an intelligent model routing angle the paper highlights: vibe coders typically throw every task at a single frontier model, paying premium token prices to fix a typo or generate a basic unit test. A well-designed agentic system routes complex tasks (architecture, initial implementation) to large models, and deterministic, low-complexity tasks (test generation, code review, CI/CD monitoring) to smaller, faster, cheaper models.
The paper's summary framing is sharp: vibe coding is a speed-to-first-output advantage. Agentic engineering is a sustainable-scale advantage.
There's a crossover point — and the paper shows it clearly — where vibe coding costs 3–10x more per feature to maintain than agentic engineering. Most teams hit that crossover somewhere between their third and fifth shipped feature.
My take as an architect: I've watched this pattern play out on real teams. A startup ships an MVP in two weeks of vibe coding. Three months later, they're spending more time fighting AI-generated technical debt than building new features. The economics flip fast, and they flip hard. The CapEx of agentic engineering isn't a luxury — it's the investment that keeps your marginal feature cost from compounding into an unmaintainable system. Build the harness before you need it. You will need it.
Putting It All Together
The teams that will win aren't the ones with the fastest prompt-to-code pipelines. They're the ones who build systems that produce reliable, verifiable, maintainable software at scale — with AI handling implementation and humans retaining ownership of specification, architecture, and quality.
Three durable principles the paper lands on:
Structure scales, vibes don't.
Vibe coding is valid for exploration. For software organizations depend on, agentic engineering discipline is not optional.
AI amplifies your engineering culture.
Strong testing practices + clear architectural standards = dramatically more value from AI tooling. Weak culture × AI = faster accumulation of technical debt.
The human role is evolving, not diminishing.
The skills that matter are shifting from implementation to judgment — from writing code to designing the systems that produce code.
What I'm Taking Away
As someone who's been building with and around AI agents for a while now, this paper validated a lot of things we've been doing on the tooling side — and gave me cleaner language for a few things I'd been hand-waving around.
The harness framing is the biggest unlock for me. Treating AGENTS.md, skill files, eval suites, and sandbox configs as first-class engineering artifacts — reviewed, versioned, and owned — is the single change that separates teams using AI from teams leveraging AI.
The static vs. dynamic context split is the second. Every context file review in my team now starts with the question: "Does this belong in static context or dynamic?" It's a forcing function for cleaner agent design and lower token costs.
And the economics framing is what I'll use in every conversation with leadership about AI tooling investment. This isn't a subscription. It's a CapEx decision with OpEx implications. Make it deliberately.
Read the full paper: The New SDLC with Vibe Coding — Addy Osmani, Shubham Saboo, Sokratis Karakis (Google, May 2026)
View brief on youtube:
Have thoughts on where your team sits on the vibe coding ↔ agentic engineering spectrum? Drop a comment or reach out on LinkedIn.
💌 Want more breakdowns like this every weekend? Subscribe to the SlayItCoder Newsletter
Connect with me: