
Introduction:
In this post, I’ll walk through a machine learning project where I built a rent prediction model using Random Forest and Linear Regression. We’ll load the dataset, clean it, train two models, and compare their performance using Mean Squared Error (MSE).
Dataset Overview:
Source: Kaggle dataset - House Rent Prediction
Features:
BHK (No. of Bedrooms)
Size (sq ft)
City
Furnishing Status
Floor Info
Area Type / Locality
Bathroom Count
Tenant Preferences
Preprocessing:
Encoded categorical features like City, Furnishing Status
Extracted floor info
One-hot encoding and label encoding
Used
train_test_split(test_size=0.2, random_state=42)
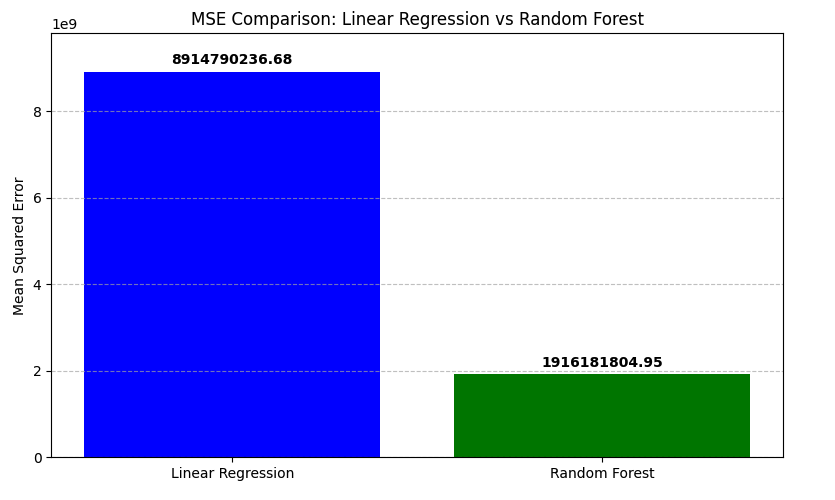
Models:
Trained two models:
LinearRegression()RandomForestRegressor(n_estimators=100)
Collab Link: link
Conclusion:
Random Forest is a strong choice for house rent prediction. For production, I'd next explore hyperparameter tuning and feature importance analysis.
💬 Final Words
You're reading my Weekend Logs — short, powerful reads every Saturday & Sunday for working professionals curious about AI, tech, and the future.
🧠 Learn one concept ⚒️ Try one tool 🚀 Build one small thing
That’s it. Do that weekly, and you'll be ahead of 99% of your peers.
📣 Bookmark. Share. Follow. And if you liked this — tell me. I respond to every message.