
I’ve always wondered how recommendation engines know what we might like next. Instead of just reading about it, I’m building one from scratch — and sharing each step.
We’ll use the MovieLens 100K dataset and follow a clear roadmap:
Blog 1 – Dataset setup, cleaning, baseline models, and SVD personalization
Blog 2 – Two-Tower Neural Network
Blog 3 – API integration, frontend, deployment, and wrap-up
In this first post, we’ll cover:
Choosing the dataset (Where’s my data?)
Cleaning it (Can I trust my data?)
Building baseline recommenders (What’s popular?)
Using SVD(Singular Value Decomposition) for personalization (Breaks the One-size-fits-all Problem)
Step 0 — Our Game Plan
What problem are we solving?
We want a working pipeline that: loads data → cleans it → gives baseline insights → builds a personalized recommender. This roadmap shows the full path.
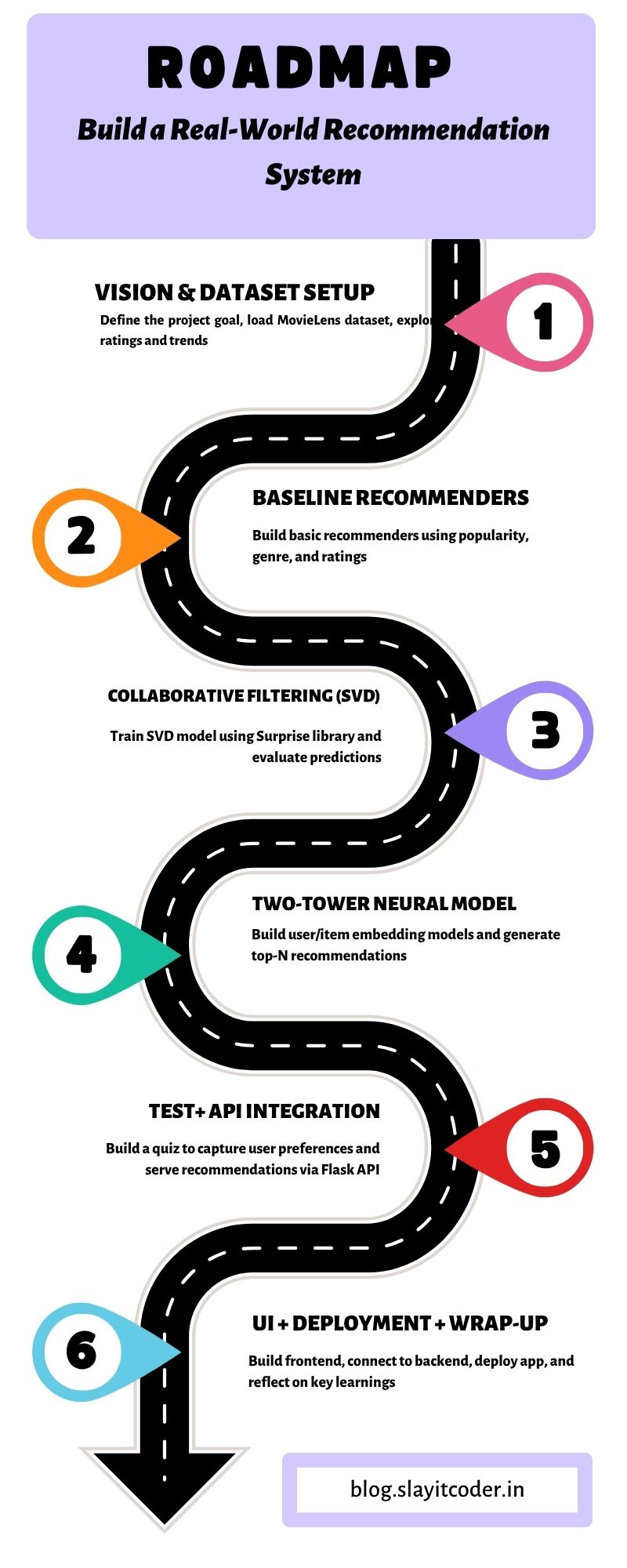
Figure 1. Project roadmap — six milestones from dataset setup to deployment.
Step 1 — Picking the Dataset
Problem solved: Where’s my data and is it fit for purpose?
We chose MovieLens 100K because it’s:
Real user ratings (good signal)
Includes movie titles + genres (enables content signals)
Small enough to iterate quickly but large enough to be realistic
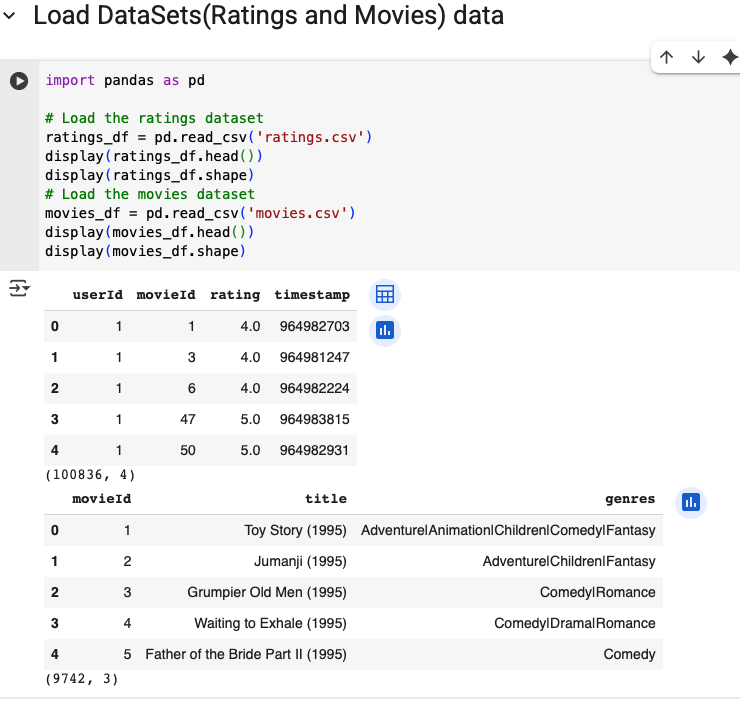
Figure 2. Snapshot of `ratings.csv` and `movies.csv`. Ratings, movie titles and genres are the core columns we use.
Why this matters: Selecting a dataset that contains both interactions (ratings) and item metadata (genres) lets us try both collaborative and content-aware methods later.
Step 2 — Cleaning the Data
Problem solved: Can I trust the data?
Key checks and fixes performed:
Merged ratings + movies so each rating has a title and genre.
Dropped movies with (no genres listed) — they don’t help genre-based logic.
Ran quick bot detection (very fast repeated timestamps). We flagged or removed obvious anomalies to avoid biasing models.
Step 3 — Baseline Recommenders (Popularity & Genre)
Problem solved: What does “the crowd” actually like?
Before building anything personalized, we must know the baseline. These are the things your system must beat.
Most popular (global)
Compute avg_rating and rating_count for each movie
Filter by a minimum rating count (e.g., ≥ 50) so small-sample winners don’t dominate
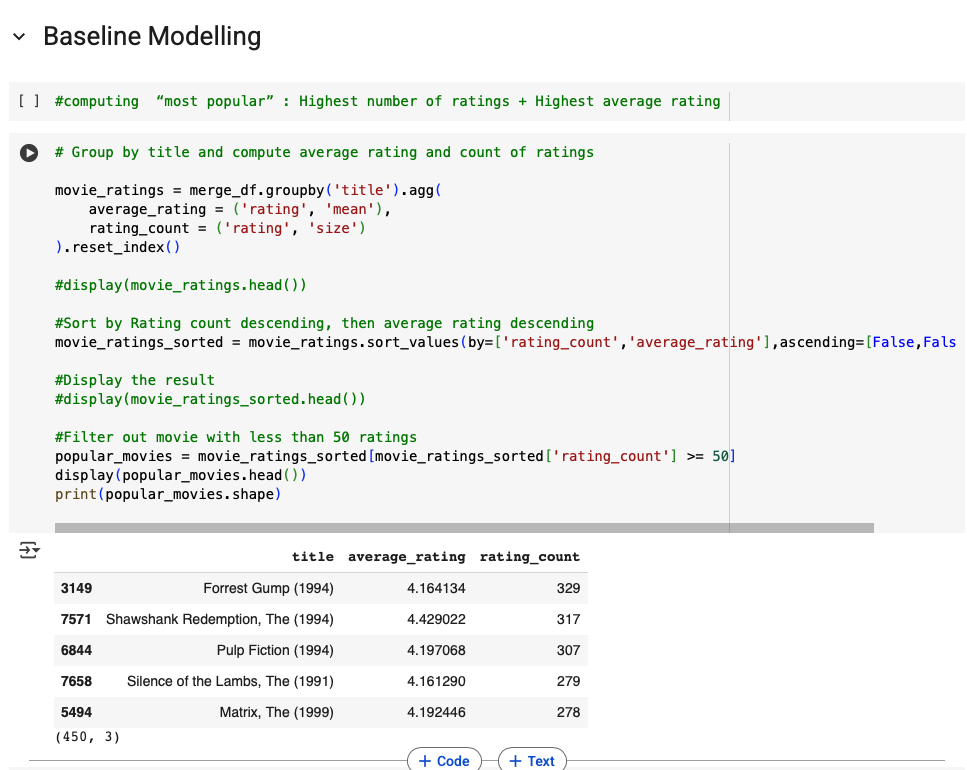
Figure 3. Top popular movies (min 50 ratings). Combines popularity (count) and quality (avg rating).
Top movies per genre
Expand genres (split by |), compute per-genre average and counts
Filter (e.g., ≥ 20 ratings) and show top-N per genre
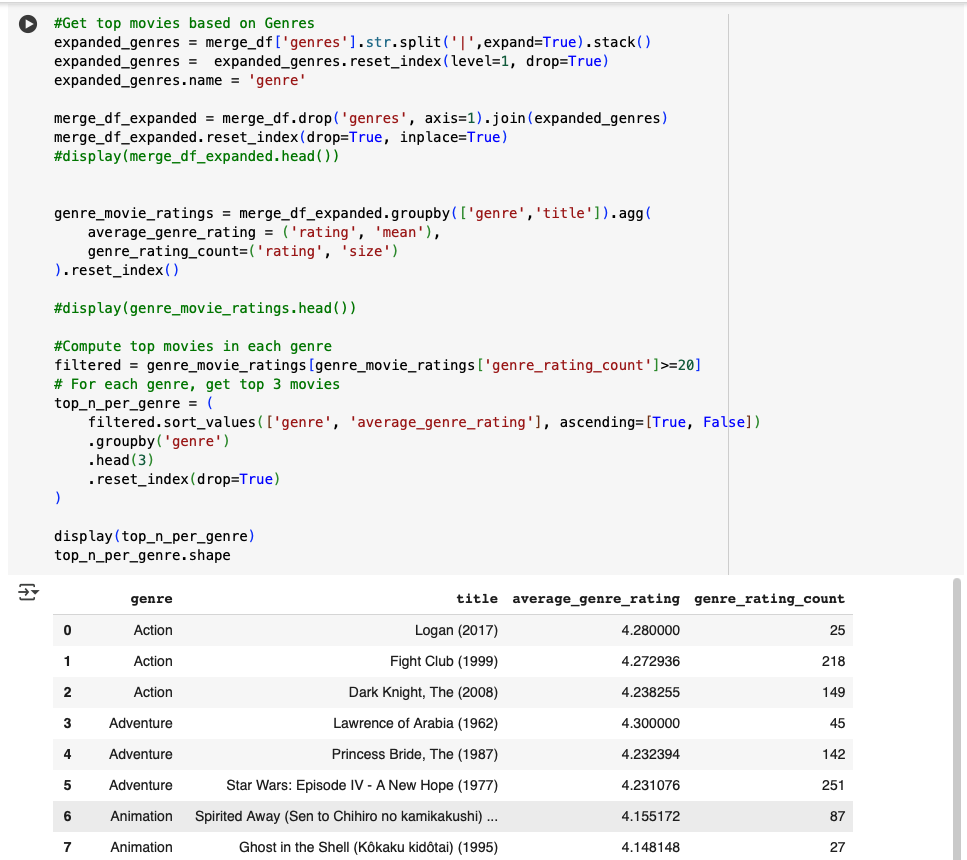
Figure 4. Top 3 movies in several genres (min 20 ratings). Useful for cold start and contextual lists.
Why baselines matter:
Cold-start fallback for new users
Performance baseline (if SVD or NN cannot beat them, check your pipeline)
Quick user-facing features (Top 10, By genre) while building advanced models
Step 4 — Collaborative Filtering with SVD (Personalization)
Problem solved: Move beyond “one-size-fits-all” to truly personalized recommendations.
Short explanation: SVD is a matrix factorization technique that decomposes the user–movie rating matrix into latent user features and latent item features. Multiplying those factors reconstructs predicted ratings for every (user, movie) pair — enabling personalized ranking.
Small SVD flow brief (to include right above the diagram):
Start: sparse User × Movie rating matrix (rows = users, cols = movies).
Decompose: R ≈ U × Σ × Vᵀ.
U = user latent matrix (users → latent features)
Σ = diag(singular values) (importance of each feature)
Vᵀ = movie latent matrix (latent features → movies)
Reconstruct: U× Σ × Vᵀ → predicted ratings for all unseen pairs.
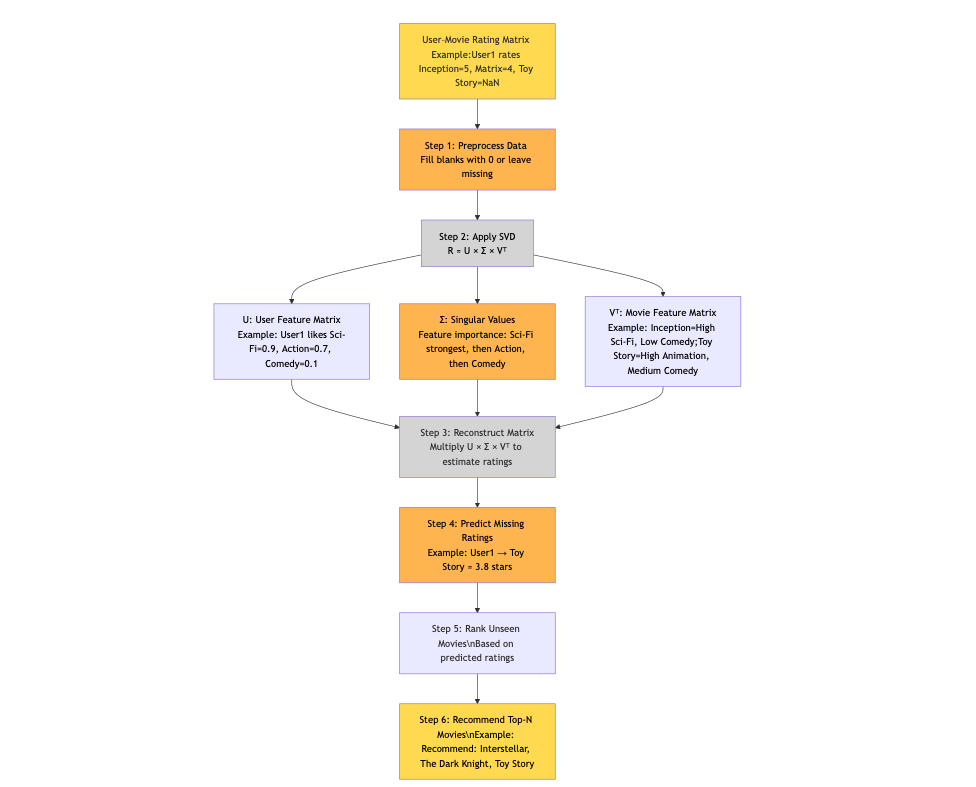
Figure 5. SVD pipeline: preprocess → decompose → reconstruct → predict → recommend.
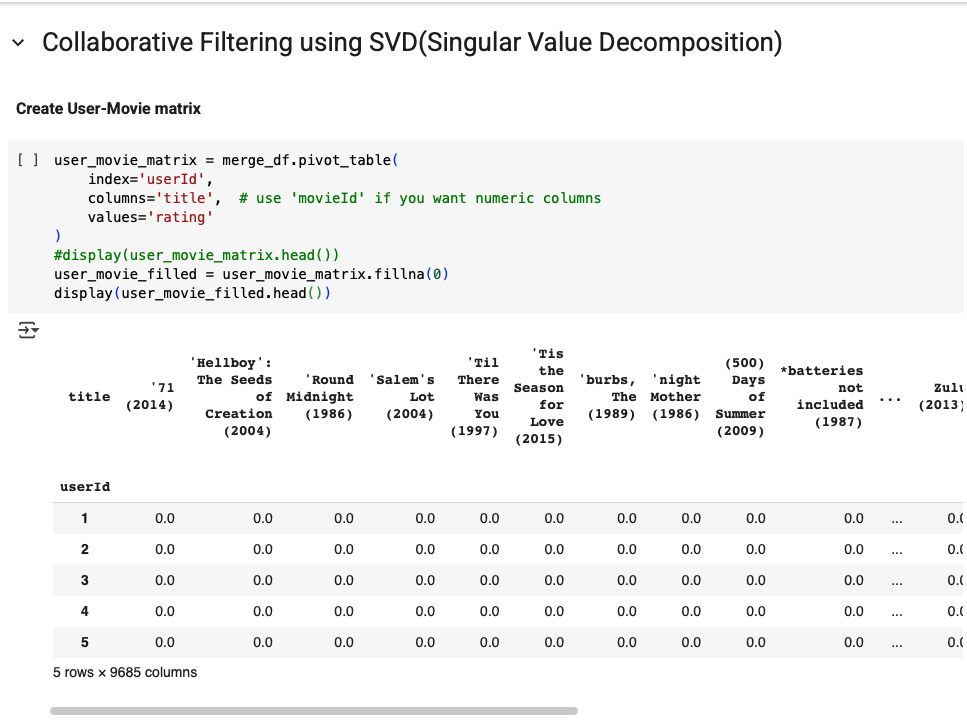
Figure 6. Example user–movie matrix after pivoting (many NaNs shown as 0 when filled).
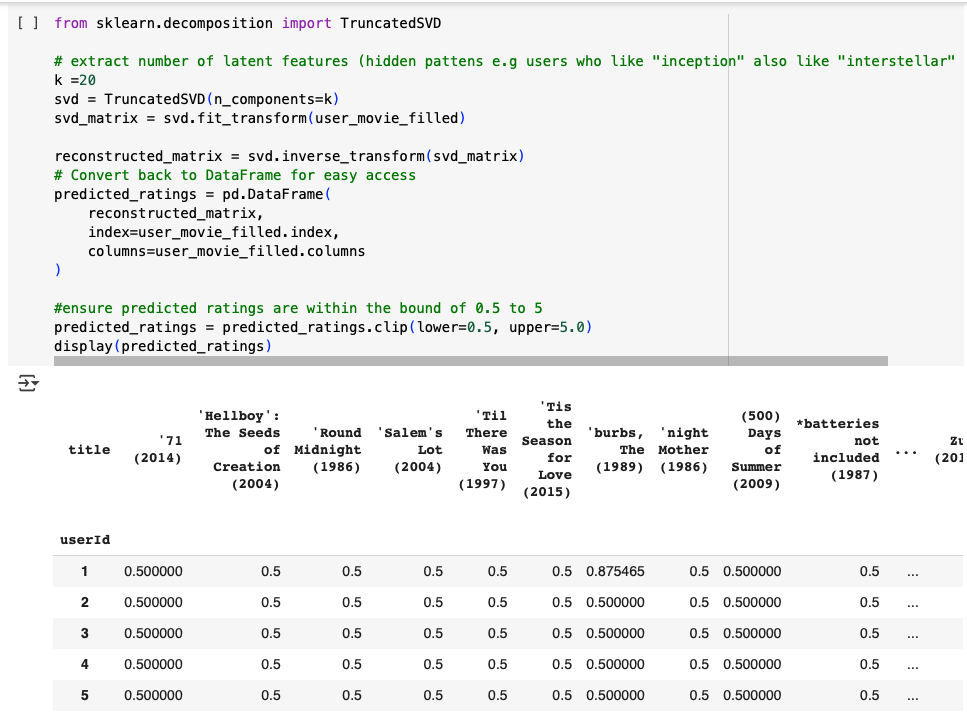
Figure 7. Visual of reconstructed predictions (sample rows) — shows predicted scores for all movies.
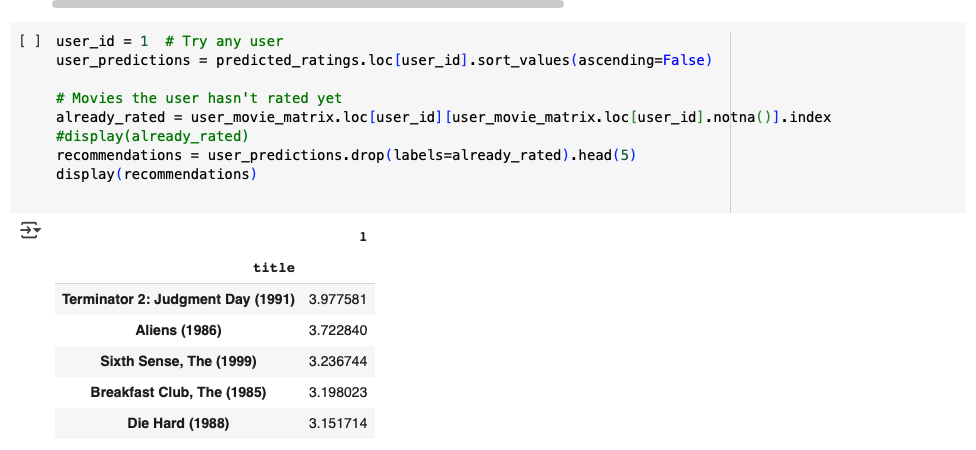
Figure 8. Example top-5 recommendations for user 1 (predicted ratings sorted).
Why SVD matters (practical takeaways):
Learns latent tastes (not explicit genres) and generalizes across users
Works well with dense enough interaction data
Limitations: not ideal for true cold-start (new users or items) unless combined with side features
Wrapping Up — What you learned in Part 1
How to pick and inspect a dataset suitable for recommenders.
How to clean data and remove straightforward noise (missing genres, bot-like timestamps).
How to build two practical baselines (global popularity and per-genre top lists).
How SVD turns sparse ratings into personalized recommendations and where to place it in a production pipeline.
Where We Are (Progress Table)
Step | Description | Status |
|---|---|---|
1 | Vision & Dataset Setup | ✅ |
2 | Baseline Recommenders | ✅ |
3 | Collaborative Filtering (SVD) | ✅ |
4 | Two-Tower Neural Model | ⬜ |
5 | Test + API Integration | ⬜ |
6 | UI + Deployment + Wrap-up | ⬜ |
All code for this post is in the Colab notebook: link
More from the Author
📝 Blog: https://blog.slayitcoder.in
📬 Newsletter: https://slayitcoder.substack.com
💼 LinkedIn: Pushkar Singh