
Can Machines Really Remember? Let’s Explore RNNs
In the last post, we explored AutoRegressive (AR) models — where predictions rely on a fixed number of previous values (P). But what if the key to your next move lies way further back?
Imagine reading a mystery novel. The killer was hinted at in chapter 2, but you're now in chapter 20. AR models wouldn’t remember that far. But humans do. Can machines?
Let’s find out how neural networks started remembering the past — introducing Recurrent Neural Networks (RNNs) and their smarter cousin, BiRNNs.
🚧 The Limits of AR Models
Limitation | What It Means |
Fixed memory window (P) | Only last few inputs matter |
No learnable context | Treats all past inputs equally |
Weak for complex sequences | Can’t track long-term patterns |
AR models are like goldfish: efficient, but with short memory. For deeper insight, we need something smarter.
🔁 Meet RNNs: The First Step Toward Memory in Machines
💡 Historical Context: RNNs were introduced in 1986 by David Rumelhart et al. in their paper: 👉 “Learning Internal Representations by Error Propagation”
This was the beginning of networks that learn across time, not just in space.
🧠 What Makes RNNs Special?
RNNs process input step-by-step, and carry forward a hidden state — like a running memory.
📘 Example: Imagine processing this sentence:
"The cat sat on the..."
An RNN uses previous words to guess the next one — “mat” makes more sense than “spaceship” because it recalls the context.
Each step looks like this:
Input (xt) + Hidden State (ht-1) → New Hidden State (ht) → Output
This loop creates temporal awareness, allowing RNNs to track dependencies across time.
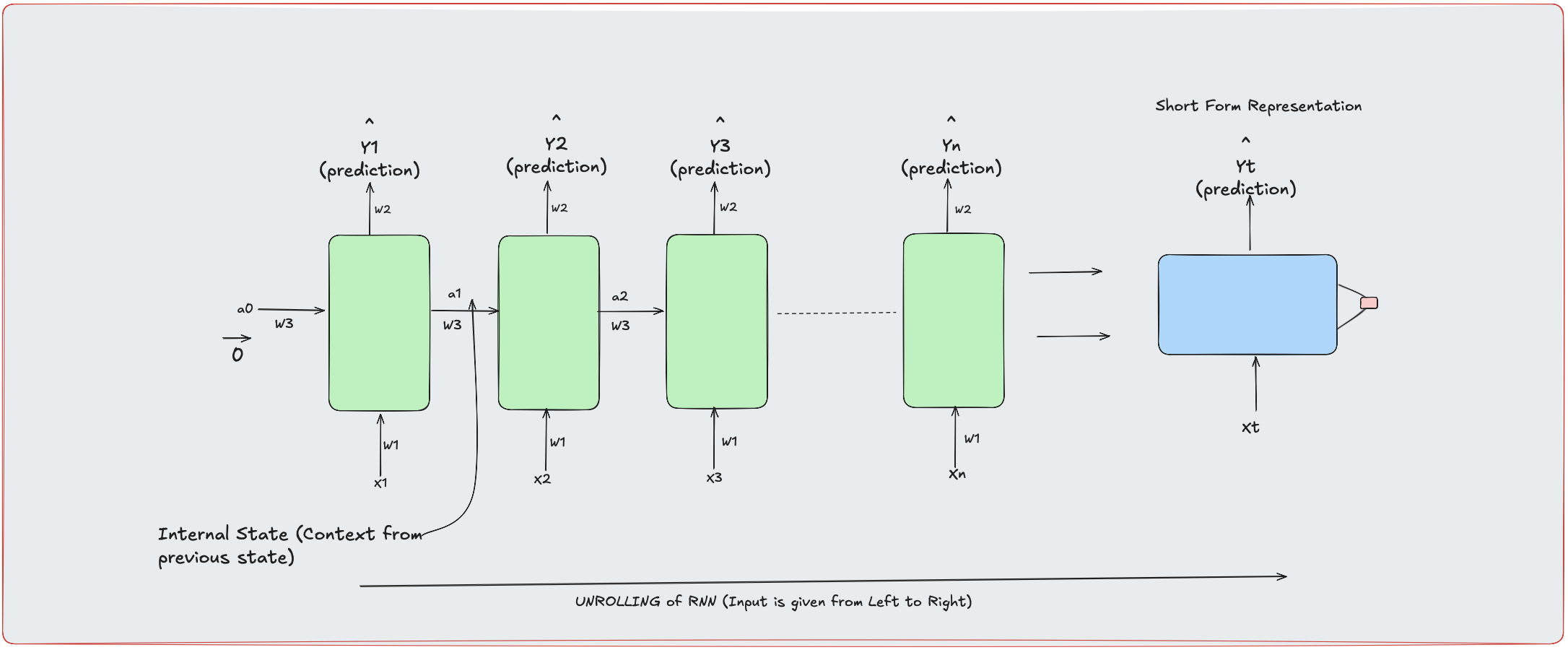
Figure 1: Unrolling of a Recurrent Neural Network (RNN). Each time step shares the same weights 'w' and passes context 'a' forward, building a memory of the sequence.
🔁🔁 BiRNNs: Look Back AND Ahead
Let’s look at a fun example that shows how context matters:
📘 Sentence 1: "Teddy Roosevelt was the prime minister of USA."
📘 Sentence 2: "Teddy bear is a soft toy."
In both, the word “Teddy” appears — but its meaning is different. A standard RNN reads left to right and may treat "Teddy" as a proper noun in both cases, potentially confusing the toy with the person.
Why? Because it hasn’t yet seen the full sentence — especially the important part: "soft toy."
💡 This is where BiRNNs shine:
They read the sentence in both directions — from start to end and end to start.
This means the network knows in advance that “Teddy” is followed by “bear is a soft toy” — helping it disambiguate the meaning.
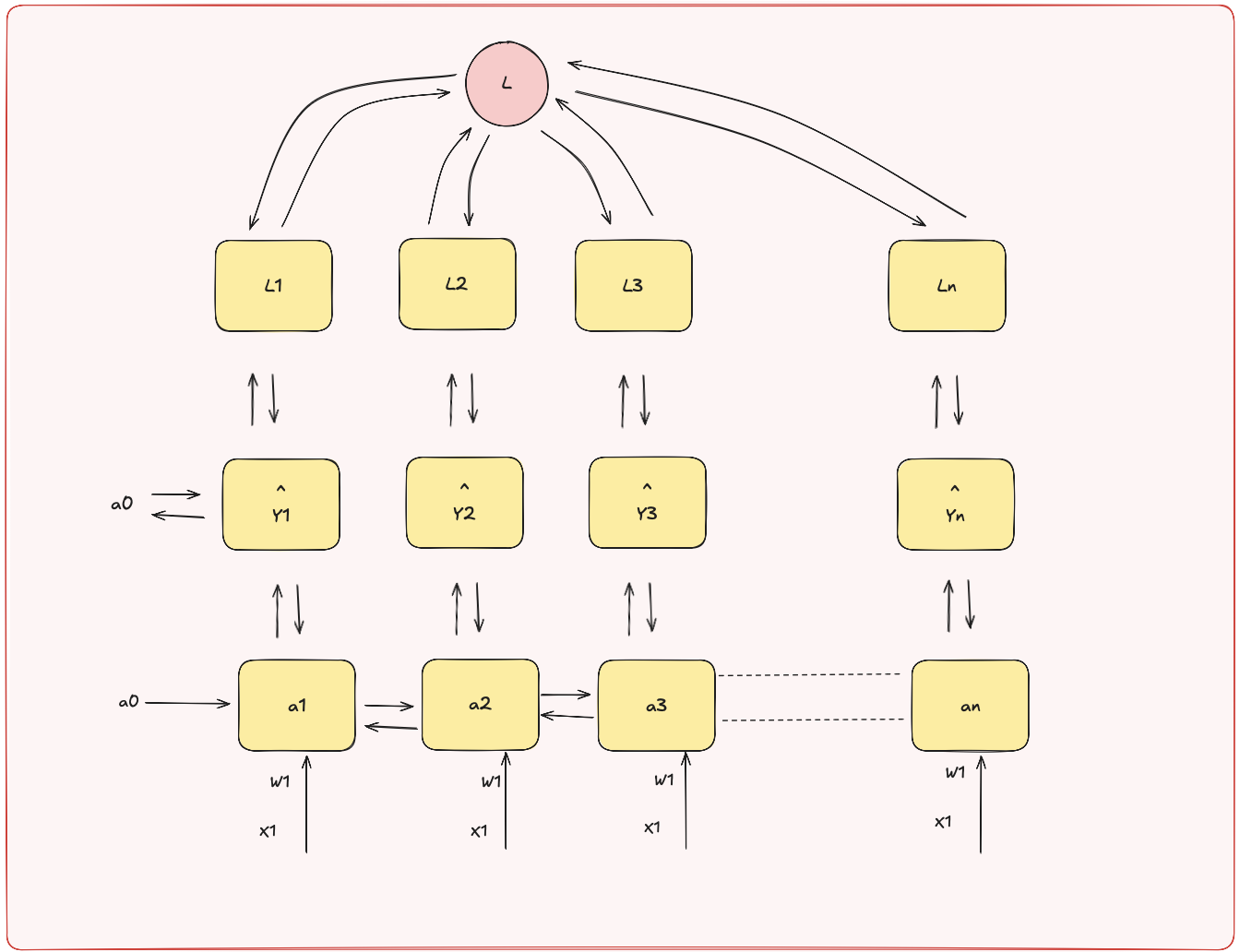
Figure 2: Bidirectional RNN (BiRNN) processing the same sequence from both left-to-right and right-to-left. Each cell captures information from the future as well as the past.
So while RNNs carry memory from the past, BiRNNs are like having eyes on both the past and the future.
We humans also often understand something better after reading more — BiRNNs try to do the same.
🏋️♂️ How RNNs Learn: Backpropagation Through Time
Training RNNs isn’t just about feeding data forward — we must also pass errors backward across time steps. This is called Backpropagation Through Time (BPTT).
⏳ Why is it hard?
Gradients must pass through many time steps
They can vanish or explode, hurting learning
⚠️ This is why RNNs struggle with very long sequences — and why LSTM/GRU were invented (stay tuned!).
⚙️ Try It: Code Sample
Let’s build a basic RNN using PyTorch to classify sentiment on a sentence — a hands-on way to see how these models learn from sequences.
import torch
import torch.nn as nn
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleRNN, self).__init__()
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
out, _ = self.rnn(x)
out = self.fc(out[:, -1, :]) # Use the last time step's output
return out
# Example input: batch of 2 sequences, each of length 5, each word is 10-dimensional
sample_input = torch.randn(2, 5, 10)
model = SimpleRNN(input_size=10, hidden_size=16, output_size=2)
output = model(sample_input)
print("Output shape:", output.shape)
🧠 You can now integrate this with a dataset like IMDb or SST for real sentiment classification. This shows how RNNs handle sequence learning — word by word.
Want to try a more advanced model? Use nn.LSTM or nn.GRU in place of
nn.RNN.
✅ Where to Use RNNs
Application | Benefit of RNNs |
Sentiment Analysis | Understands tone over a sequence |
Speech Recognition | Retains word timing/context |
Stock Prediction | Learns from past time windows |
🚀 What’s Next?
Next up in the series: LSTMs & GRUs — memory units with gates that choose what to remember, forget, or pass forward.
📌 You’ll learn:
Why vanilla RNNs fail for long sequences
How LSTM’s gates solve that
📚 Keep Learning with Me
📬 Join the newsletter on Substack for practical AI insights
Let’s keep time traveling with AI — one model at a time.