
Let’s be honest — the first time someone explains LSTM to you, it sounds like they're trying to cast a spell:
“Take the hidden state from the past, mix it with the input of the present, sprinkle in some sigmoid, tanh, multiply a bit, and ta-da! Memory!”
😵 Confused? You’re not alone.
So today, we’re breaking the curse. No more boring equations without context. We're explaining LSTM like it deserves — with drama, emotion, and a little bit of kung fu.
Why Plain RNNs Are Like That One Friend Who Forgets Everything
RNNs are designed to remember what happened before and use it in future predictions. But they’re… forgetful. Like really forgetful.
They struggle with long-term dependencies, lose grip over old context, and often get overwhelmed by too much info this phenomenon is called problem of Vanishing and Exploding Gradients.
In short: they’re your friend who says, “Wait… what were we talking about again?”
Enter LSTM — The Memory King
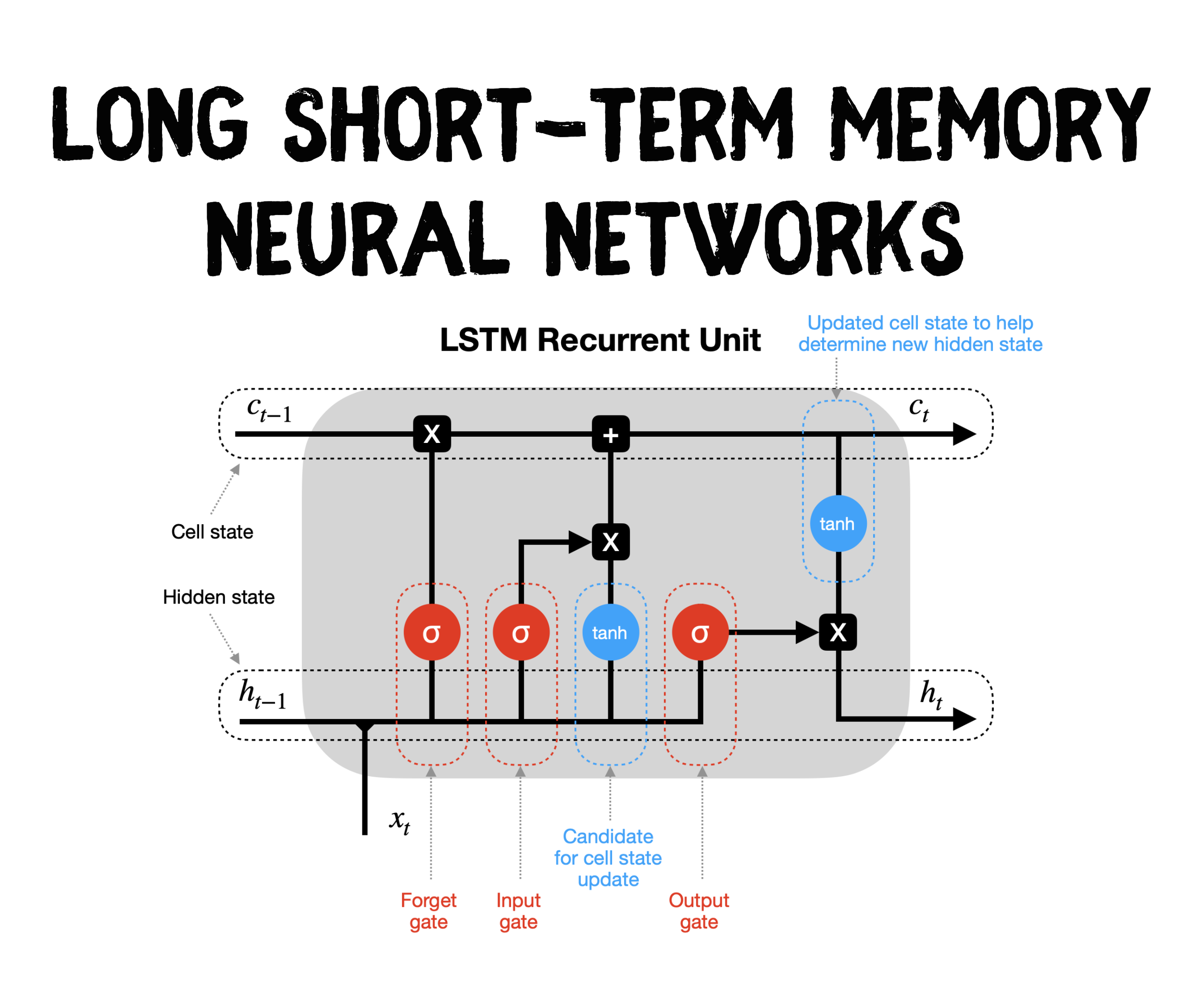
LSTM (Long Short-Term Memory) is like a wise old monk-meets-hard-disk. It decides:
What to forget
What to learn
What to say out loud
And it does all this through three clever gates: Forget Gate, Input Gate, and Output Gate.
Now let’s decode each one using movie moments you’ll never forget.
🧹 Forget Gate – ZNMD: Arjun’s Underwater Awakening
🎥 Scene: Arjun (Hrithik Roshan), a money-obsessed corporate machine, goes scuba diving. No phones. No emails. Just silence and breath.
In that stillness, he finally realizes: “This — this is living.”
He lets go of the obsession with money. He forgets what doesn’t matter anymore.
🤖 In LSTM: That’s exactly what the Forget Gate does.
It looks at the old memory Cₜ₋₁ and decides what part of it should be deleted. It applies a filter between 0 and 1 to each memory element:
0 = “Ahh, forget this.”
1 = “Keep this, it’s still important.”
So if Arjun’s mind = cell state, the Forget Gate just did an emotional detox.
🧠 Input Gate – Kung Fu Panda: Po Gets It
🎥 Scene: Po: “But... I’m not the Dragon Warrior.” Oogway: “There is no secret ingredient.” Po: brain.exe has rebooted
At that moment, Po accepts something new — a truth that reshapes his future. He lets that information in and makes it a part of who he is.
🤖 In LSTM: The Input Gate decides what new information is worth storing.
It goes like this:
First, ask: “Is this useful?” → sigmoid filter
Then: “What does this info mean?” → tanh interprets
Finally: “Add it to memory?” → Combine both and store
LSTM doesn’t add everything. Just like Po doesn’t believe every scroll or scroll-holder. Only life-changing wisdom gets saved.
🗣️ Output Gate – 3 Idiots: Rancho Says “All Is Well”
🎥 Scene: Things are falling apart. Rancho places his hand on his heart and says: “All is well.”
It’s not denial. It’s smart response. He chooses the right words to calm the storm.
🤖 In LSTM: The Output Gate decides what part of the memory is ready to be expressed.
It looks at the cell state
Applies a tanh layer to compress emotions 😅
Then filters with a sigmoid gate to decide what’s worth saying
Only the useful stuff comes out — like Rancho reassuring the gang when panic hits.
🎯 Summary — Or Should We Say... Recap Masala
🎭 Gate | 🎬 Scene | 🤖 What It Teaches |
Forget Gate | ZNMD – Arjun goes scuba diving | Let go of old, irrelevant beliefs |
Input Gate | Kung Fu Panda – “No secret ingredient” | Learn and store only what truly matters |
Output Gate | 3 Idiots – “All is well” | Say just enough. Not too little. Not too much. |
🧪 Try It Yourself — Without a Scriptwriter
Here’s how you’d use an LSTM in Keras:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
model = Sequential()
model.add(LSTM(64, input_shape=(timesteps, features)))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy')
model.summary()
Try feeding it movie reviews, stock prices, sensor data, or even your own storylines.
💬 Final Thoughts
LSTM isn’t just about math. It’s emotional. It’s dramatic. It’s thoughtful.
It knows when to:
Forget like Arjun
Learn like Po
Speak like Rancho
Now that’s what we call a model with range.
If you want to dwell deep into technicalities of LSTM check post from Ottavio Calzone.
💡 Like this post? There’s plenty more coming your way — don’t forget to hit that ❤️ Like and Follow for more AI + pop culture magic.
And remember — in ML and in life… “All is well.” 😄
🚀 What’s Next in Sequence Modeling?
You’ve already explored:
🔁 AR models — using the past to predict the future
🔄 RNNs — learning from sequences with memory
🧠 LSTMs — mastering what to forget, learn, and output
But we’re just getting started.
Next up: Transformers — the architecture behind BERT, GPT, and nearly every modern LLM you use today. We’ll unpack the power of Attention, the role of Encoders & Decoders, and why this shift changed the AI game forever.
📖 Suggested read:
🛠️ Beyond Theory: AI in Everyday Dev Life
While we explore how models like LSTMs and Transformers work under the hood, we're also diving into how to put AI to work — right now — in real development workflows.
📌 Just published: Fixing Security Vulnerabilities with Agentic Crews
In this post, I show how you can use CrewAI to build an agentic system that identifies and automatically fixes code vulnerabilities — no manual patching, just smart, AI-powered collaboration.
📚 More from the Author
📝 Blog: https://blog.slayitcoder.in
📬 Newsletter: https://slayitcoder.substack.com
💼 LinkedIn: Pushkar Singh