
In the last blog, we managed to get a personalized recommender with SVD. It was exciting to see how a simple matrix factorization could already give tailored results.
But something kept bothering me…
What if a movie is new and doesn’t have enough ratings?
What if we want to use genres (Action, Comedy, Romance) to improve recommendations?
What if we want the system to feel a little more… human?
That’s where Two-Tower Neural Networks come in.
Instead of just crunching ratings, we can teach the model about movies themselves (like their genres) and let users learn richer profiles.
In short:
SVD gave us “people who watched X also liked Y.” Two-Tower gives us “you like Action + Comedy? Here’s something right up your alley.”
Step 0 — The Dataset (Quick Recap)
Before we jump into Two-Tower models, let’s quickly revisit the dataset powering all of this.
We’re using the MovieLens 100K dataset, which contains:
Real user ratings (a strong, reliable signal).
Movie titles + genres (so we can bring in content information, not just numbers).
Just the right size: small enough to experiment quickly, but rich enough to feel realistic.
In Blog 1, this dataset helped us build baselines and SVD models. In this blog, we’ll reuse the same dataset — but unlock its genre metadata to go beyond matrix factorization.
Step 1 — Preparing the Data (Without Spoilers)
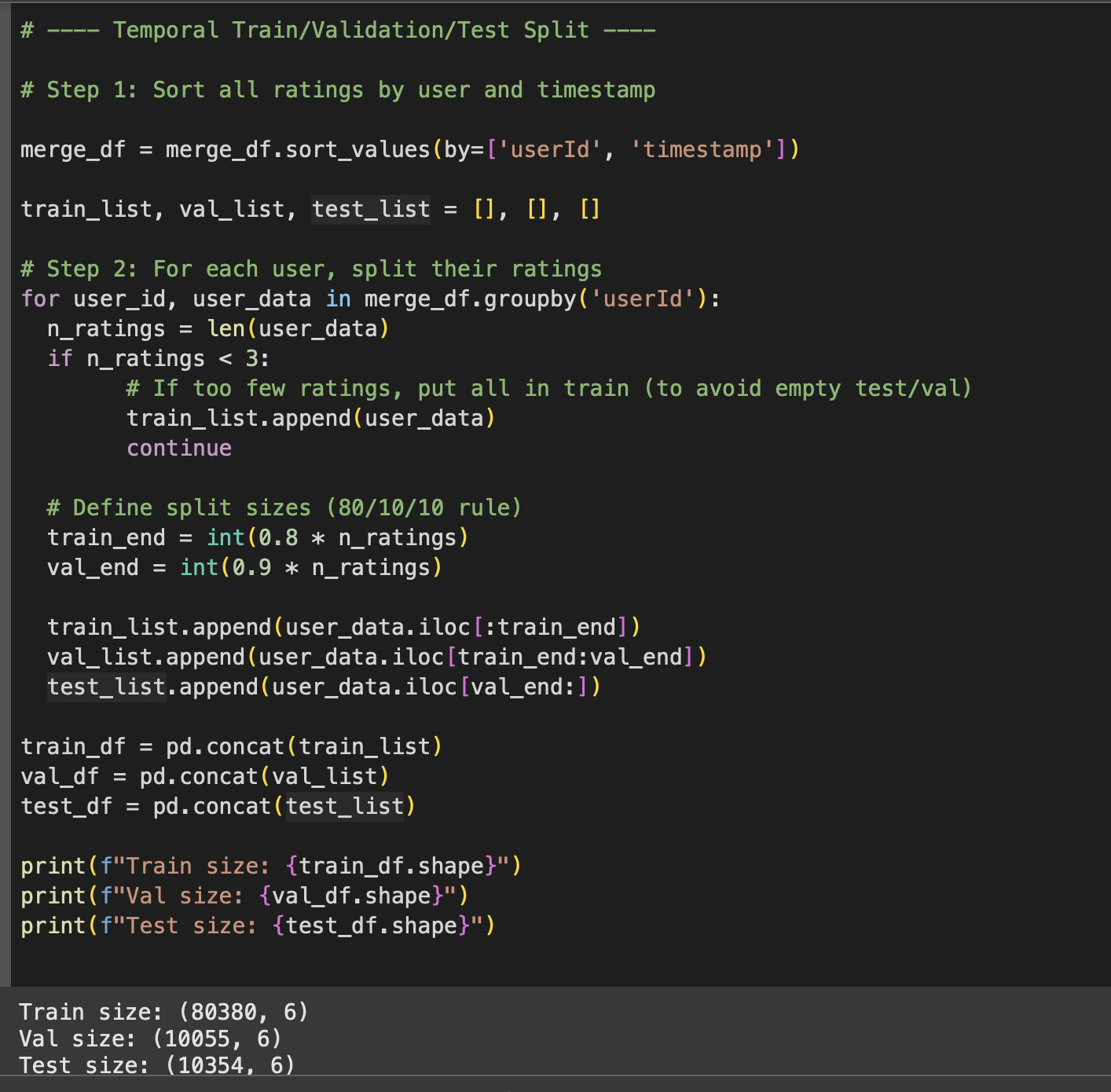
When building recommenders, one sneaky mistake is data leakage — accidentally letting the model see the future while training.
Imagine this: you’re trying to predict what you’ll watch in 2025, but your model secretly saw your 2025 ratings during training. That’s cheating.
So instead, we do a temporal split:
Train on earlier ratings.
Validate and test on later ratings.
That way, the model only sees the past, just like in the real world.
We also turn ratings into positive and negative examples:
Positive = movies rated ≥ 4.0.
Negative = random movies the user hasn’t rated.
This gives the model a contrast: “these are the kinds of movies you like, and these are the ones you don’t.”
Step 2 — Item Tower: Teaching Movies About Themselves
A movie isn’t just an ID in a database. It has genres — and genres tell us a lot.
We converted each movie’s genres into a multi-hot vector (a bunch of 0s and 1s).
Example:
Mission Impossible: Action=1, Comedy=0, Drama=0, Adventure=1.
The Dictator: Action=0, Comedy=1, Drama=0.
Now instead of “Movie 42,” the model sees: “This is an Action + Adventure film.”
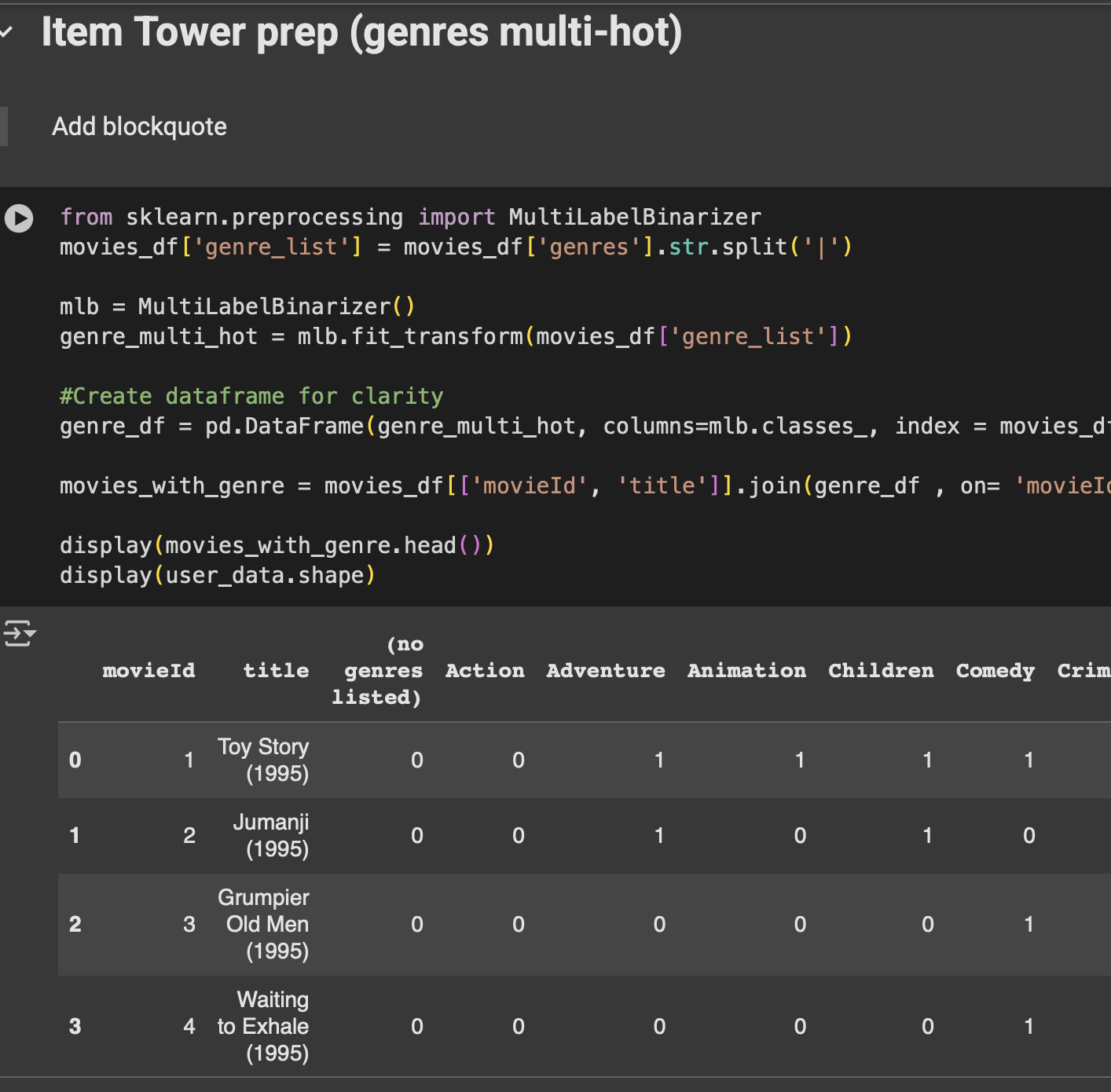
Fig: Code snippet- MultiLabelBinarizer + Genre Prep
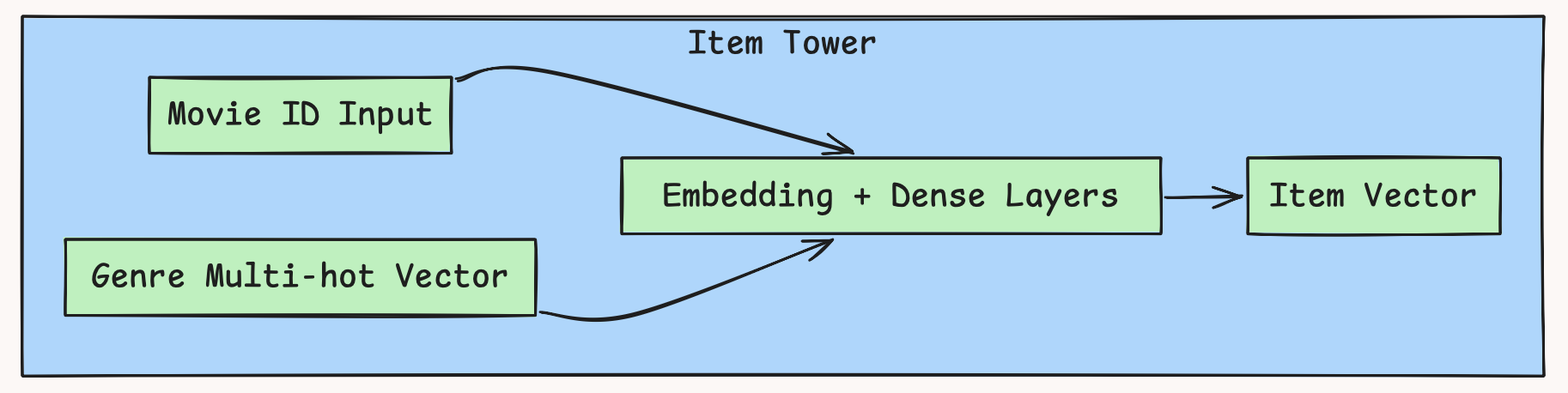
Fig: HLD showing Item Tower flow
Step 3 — User Tower: Compressing Human Taste
How do we represent a user? We can’t just say “User 5.”
Instead, we use an embedding — a dense vector that summarizes user preferences. On top of that, we stack neural layers so the model can capture deeper patterns (like “User 5 secretly loves Sci-Fi thrillers”).
The final output is a user vector that lives in the same “space” as movie vectors.
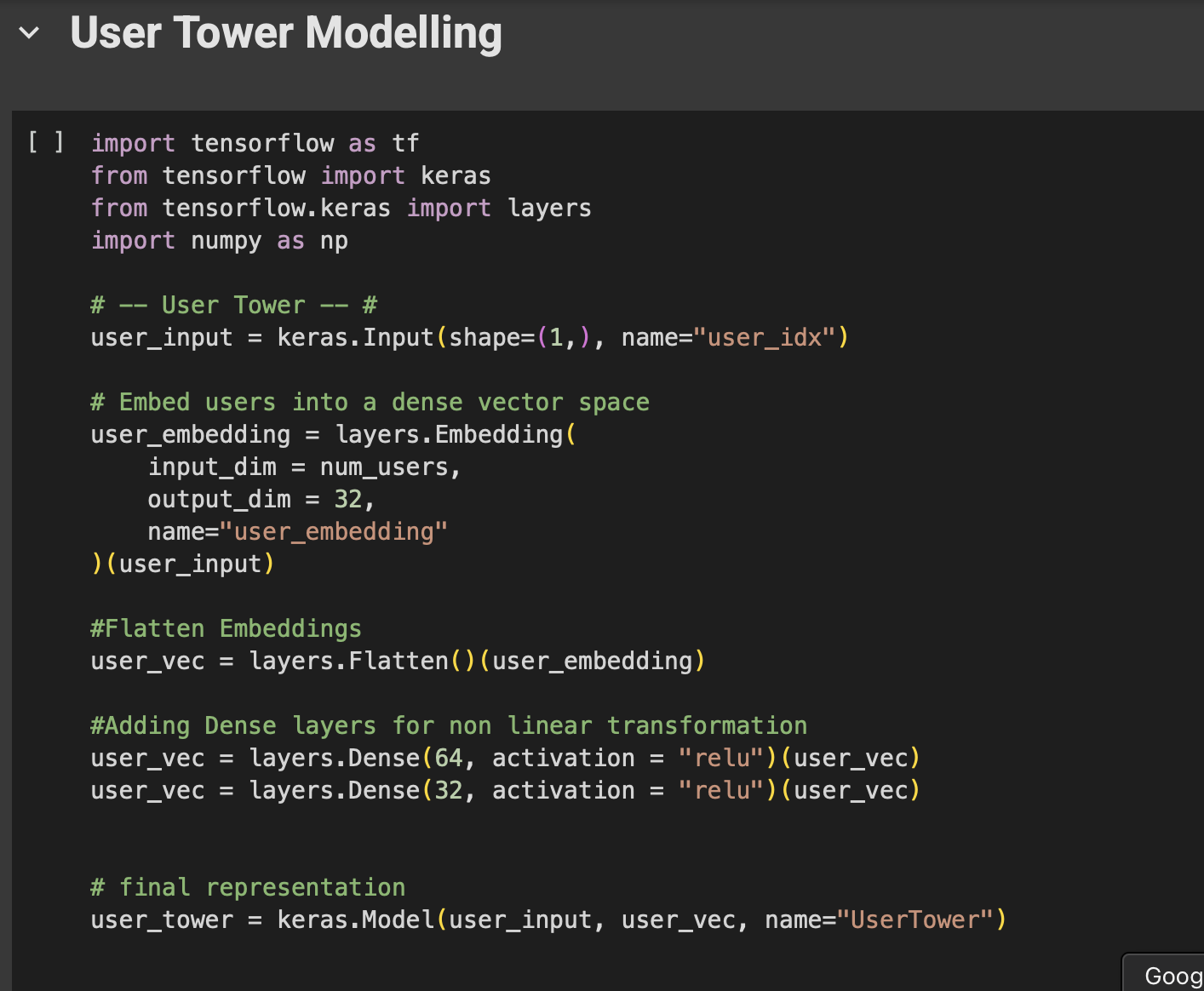
Fig: Code snippet- User Tower model

Fig: Hld for User Tower Flow
Step 4 — Where the Magic Happens
Once we have user vectors and movie vectors, we need a way to compare them.
We use a dot product: think of it as measuring how close their directions are in vector space.
Then comes the sigmoid function, which squashes that score between 0 and 1.
0 → “You probably won’t like this.”
1 → “This is right up your alley.”
That’s how the model decides.
Fig: HLD Diagram for Two- Tower Model
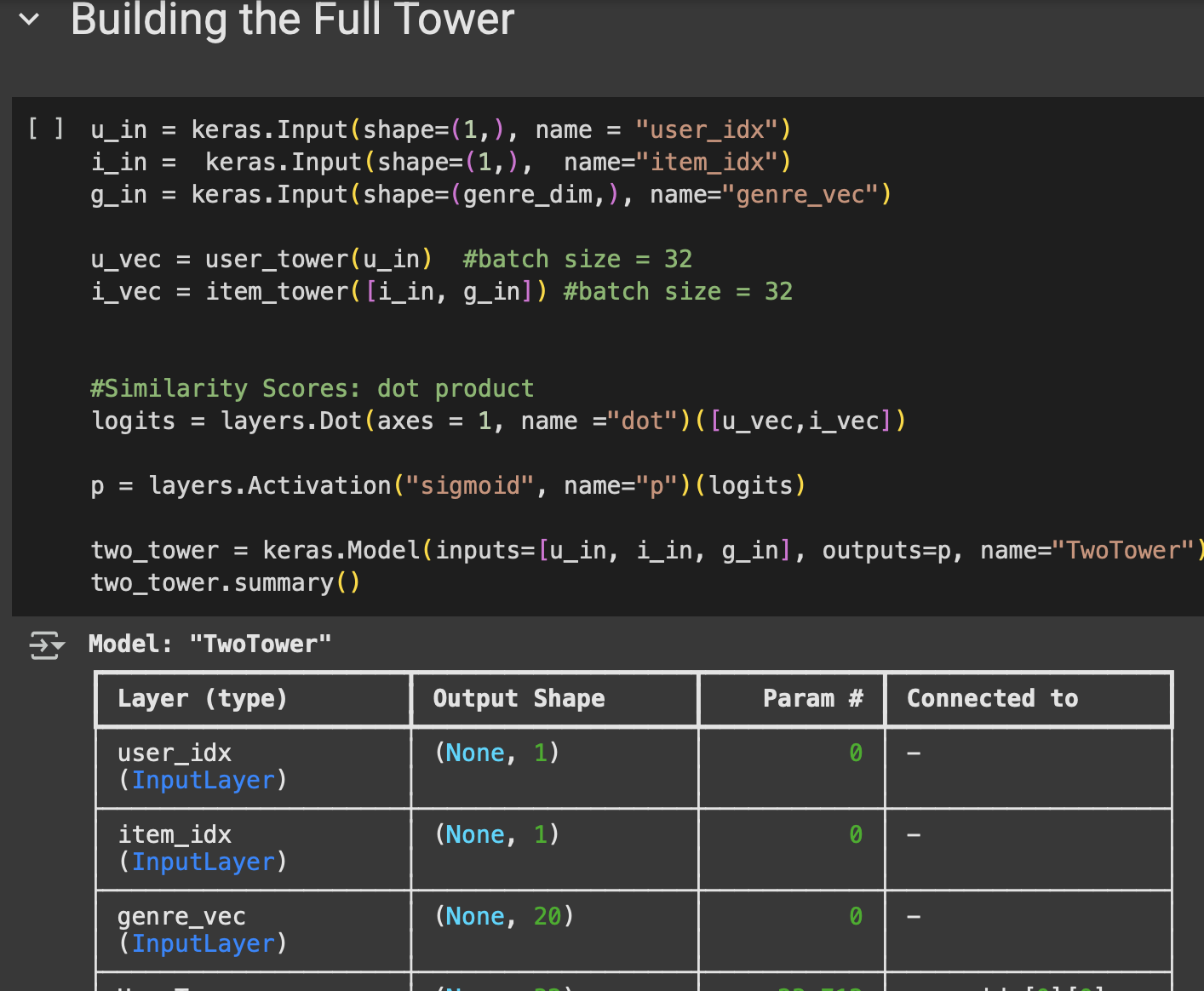
Fig: Code Snippet for Combined Model
Step 5 — Training the Model
We trained the network on our positive/negative samples. Over epochs, it learned:
Users who loved Mission Impossible also leaned towards other Action movies.
Users who loved The Dictator gravitated towards Comedy picks.
Slowly, clusters started forming in vector space — users on one side, movies on the other, pointing towards each other if they matched.
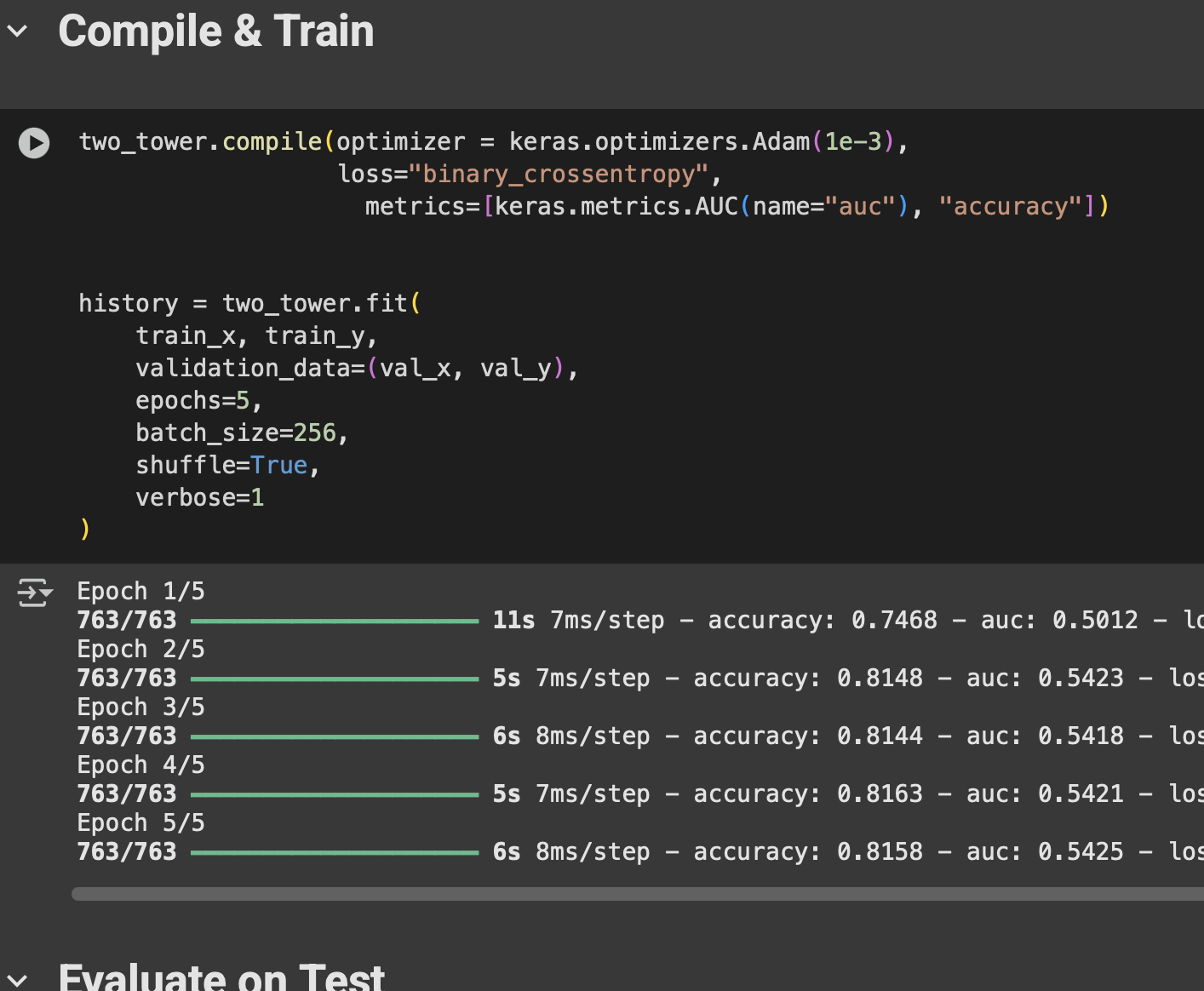
Fig: Code snippet for training loop
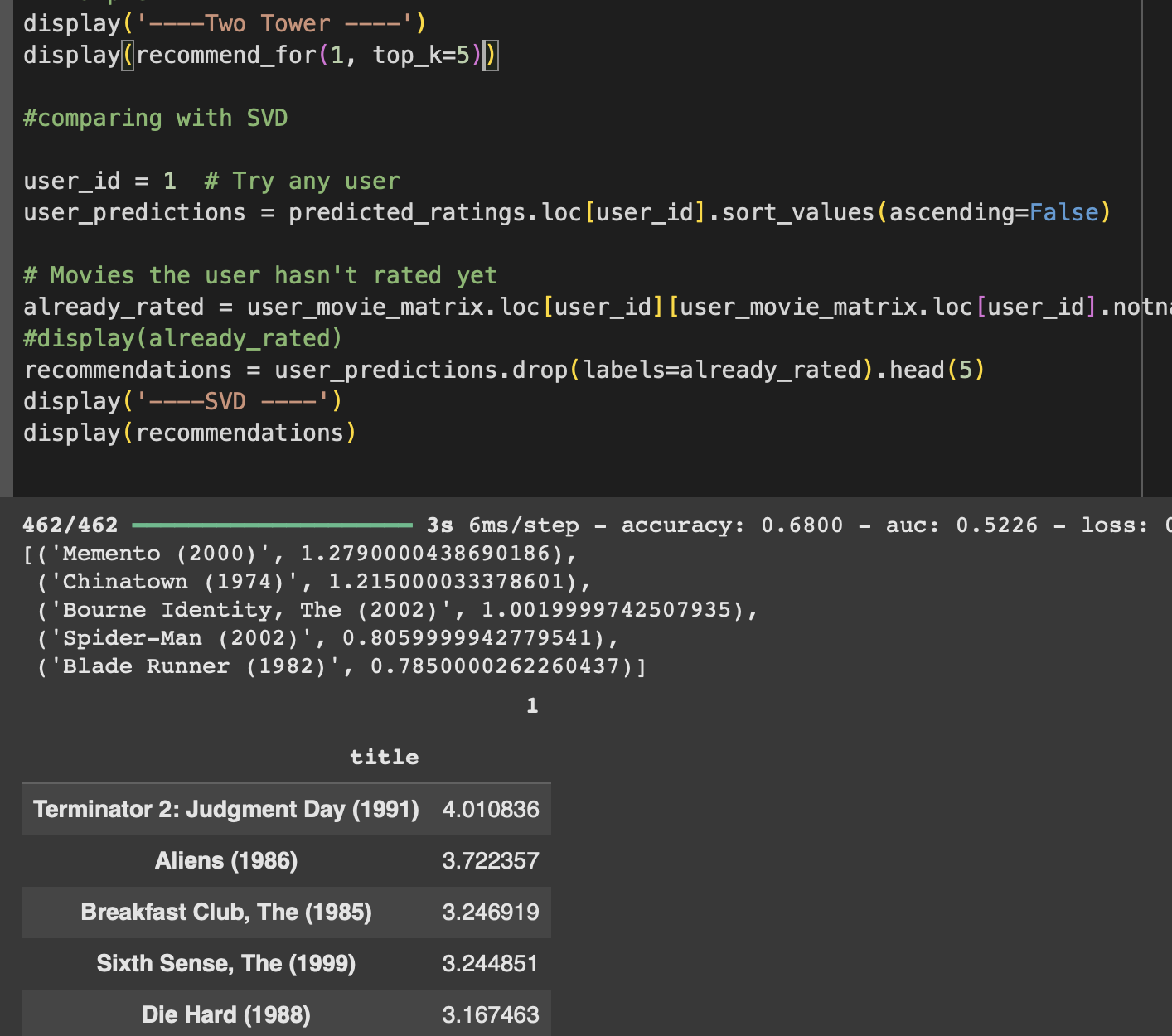
Step 6 — Comparing SVD vs Two-Tower
When we compared outputs:
SVD: surfaced movies mostly based on co-ratings.
Two-Tower: surfaced movies based on genres and side signals, even when co-ratings were missing.
That’s the edge — Two-Tower handles cold start better and uses more than just ratings.
Final Thoughts
This journey from baselines → SVD → Two-Tower shows one thing clearly: The more context we give the model (not just ratings, but genres, metadata, behavior), the more human the recommendations feel.
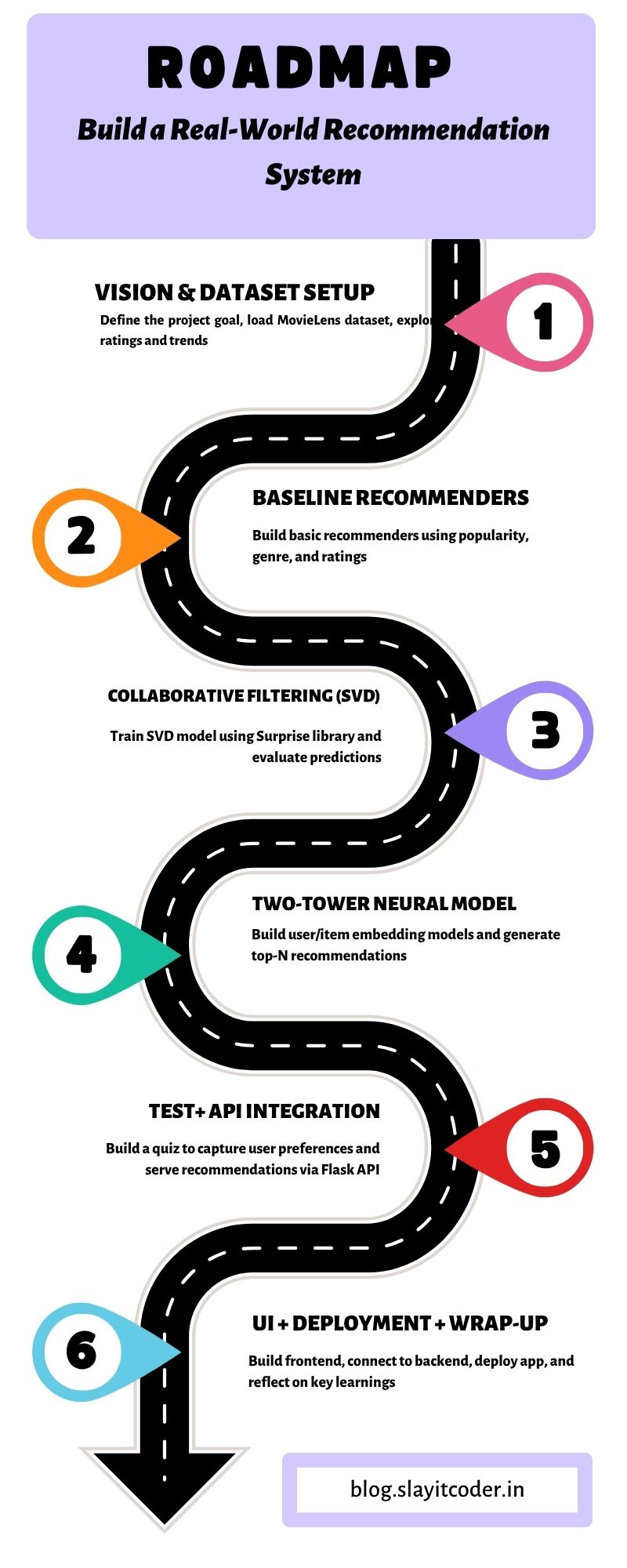
Where We Are (Progress Table)
Step | Description | Status |
|---|---|---|
1 | Vision & Dataset Setup | ✅ |
2 | Baseline Recommenders | ✅ |
3 | Collaborative Filtering (SVD) | ✅ |
4 | Two-Tower Neural Model | ⬜ |
5 | Test + API Integration | ⬜ |
6 | UI + Deployment + Wrap-up | ⬜ |
All code for this post is in the Colab notebook: link
More from the Author
📝 Blog: https://blog.slayitcoder.in
📬 Newsletter: https://slayitcoder.substack.com
💼 LinkedIn: Pushkar Singh