In Part 1, I shared the vision: AI doesn't always need the cloud. We talked about "right-sizing" intelligence using Small Language Models (SLMs) and why moving the brain to the user’s local hardware is the ultimate move for privacy and cost-efficiency.
Today, the vision is no longer a hypothesis. It’s a 4GB executable folder sitting on my desk.
In this post, I’m going to tear down the engine and show you exactly how we bypassed the "Cloud Tax" to build a system that runs at 30+ tokens per second—completely disconnected from the internet.
Watch the full demo here:
The "Zero-Cloud" Stack
When you remove AWS Bedrock and managed Vector DBs, you are left with a massive void. To fill it, we built a custom stack designed for one thing: Efficiency on Metal.
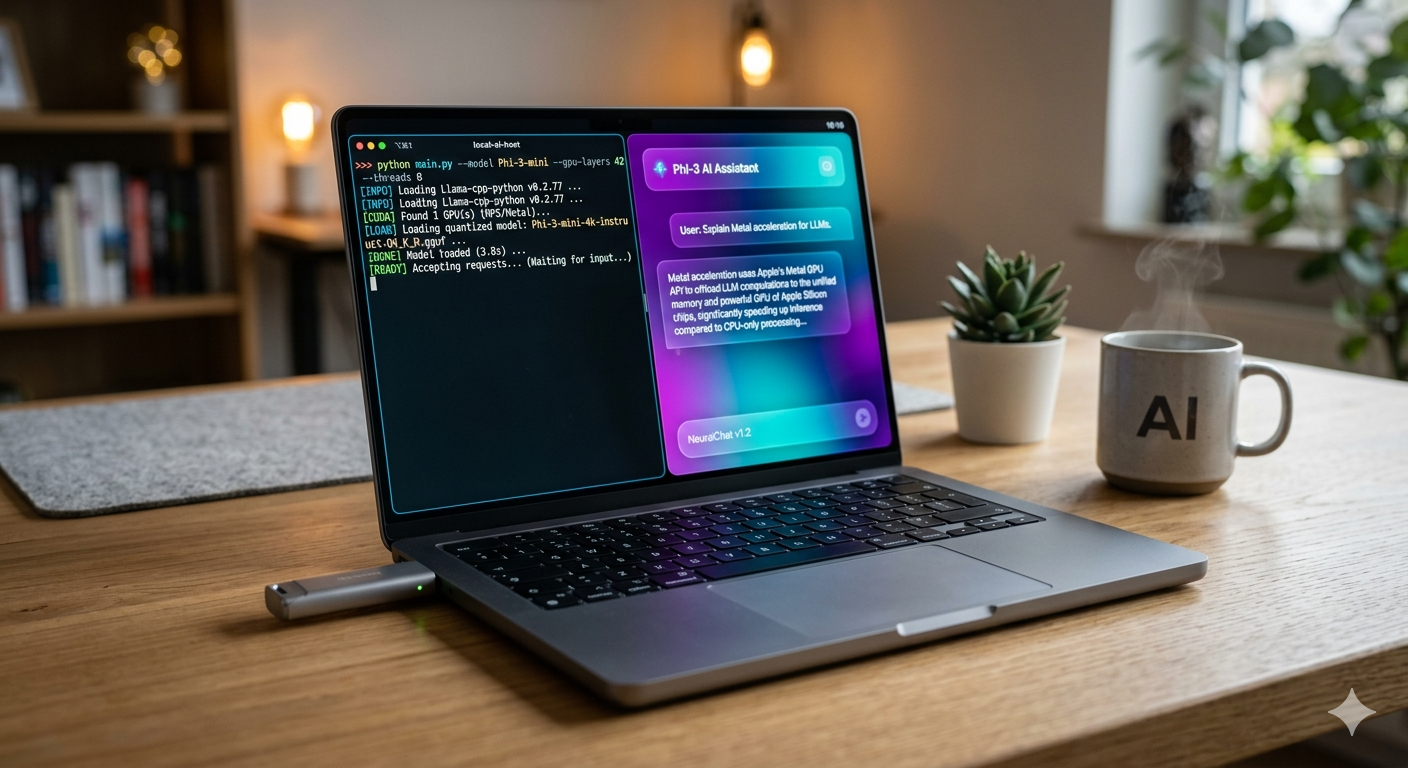
1. The Brain: Phi-3-Mini (GGUF via Llama-cpp)
We chose Microsoft's Phi-3-Mini (3.8B). In its raw form, it's a beast, but we needed it to fit in RAM alongside Chrome and IDEs.
The Format: We used GGUF, which is a quantized, memory-mapped format designed for local inference. Instead of loading a massive model into RAM, it allows efficient execution with reduced memory overhead.
The Squeeze: Through 4-bit quantization, we shrunk a ~7GB model down to 2.3GB without losing the reasoning capabilities needed for technical academic queries.
The Speed: By using llama-cpp-python with n_gpu_layers=-1 (Apple Silicon) , we offloaded the entire model to the Apple Metal API. This turned "slow CPU math" into "near-instant GPU inference" on Apple Silicon.
2. Retrieval without Cloud: FAISS + JSON Persistence
In a cloud setup, retrieval is outsourced to services like Pinecone. Offline, you are the vector database.
Vector Search: We implemented FAISS (Facebook AI Similarity Search). When a user uploads a PDF, we embed the text locally using sentence-transformers and write the math to a local .faiss index file. Here FAISS only stores vectors - not the original text, So we need a bridge.
The Context Bridge:
Since FAISS only stores vectors (not text), we built a "Recall Layer"—a chunks.json
file that maps vector IDs back to raw text. It’s simple, lightning-fast, and requires zero infrastructure.
The Challenge: Making it "Truly" Portable
One of the hardest parts of an offline transformation is making the app work anywhere. If I copy my folder to your pendrive, it shouldn't break because your disk is named Drive_Binstead of Drive_A.
Solving the "Relative Path" Crisis
Initially, our React frontend was hardcoded to look for the API at a specific cloud IP. This threw constant CORS errors and 404s when moved to a local machine.
We solved this with a Unified Serving Strategy:
Environmental Awareness: We updated the frontend build to use Relative URLs (/api/v1).
The Fast-Server: We modified the FastAPI (Uvicorn) server to act as a dual-threat. It handles the API requests and simultaneously serves the React static files.
Result: You go to localhost:8000, the server hands you the UI, and the UI talks back to the same server. No hardcoded IPs. Portability achieved.
The Final Reveal: The Pendrive Distribution
I’ve packaged the entire project into an offline/folder. It contains:
📂models/ – The "Brain" (quantized Phi-3).
📂dist/ – The compiled "Body" (React UI).
📄main.py– The "Heart" (The unified server).
📜start_offline.sh– The "Launcher" (A smart script that cleans macOS metadata and boots the system).
The Result? You can plug this pendrive into any Mac, run one script, and have a domain-expert AI assistant ready to help you study—no WiFi, no Login, no Cloud.
Closing Position
This work is not an argument against cloud AI. It is an argument against defaulting to the cloud when the problem does not require it.
As AI moves deeper into real systems—classrooms, labs, micro-frontends, and constrained environments—self-contained, localized intelligence will matter more than ever.
This series is my attempt to build that architecture, understand its limits, and document the trade-offs honestly.
🌐 Read more tutorials: https://blog.slayitcoder.in
💼 Connect with me on LinkedIn: https://www.linkedin.com/in/tpushkarsingh
🔗 Complete Code on GitHub: Offline SLM Backed RAG