
For the past year, most of my work around Retrieval-Augmented Generation followed a familiar industry pattern. Cloud-hosted LLMs. Managed embeddings. Vector databases hidden behind APIs. The systems worked, scaled, and looked “production-ready” by modern standards.
But after working closely with RAG systems , I’ve realized something: Trillion-parameter LLMs are overkill for localized context.
This isn't just a hunch; it's a vision recently validated by researchers at Samsung in their groundbreaking paper, "Less is More: Recursive Reasoning with Tiny Networks" (arXiv:2510.04871). They proved that tiny models— as small as 7 million parameters— showed that structured reasoning can emerge in smaller networks compared to models like Deepseek R1 and Gemini on complex reasoning tasks (ARC-AGI).
Today, I want to talk about the practical reality of binding a complete AI workflow into a self-sufficient distribution packet. By moving the "brain" to the user's local hardware, we address the Three Horsemen of AI projects:
Cost: Zero token costs and zero recurring infrastructure bills.
Latency: Immediate local inference without the "round-trip" to a remote cloud.
Dependency: Your app stays alive even when the Wi-Fi dies or an API provider changes their pricing.
If you envision a future where AI isn’t just a managed service but a tool you truly own—and if you feel inspired to build something meaningful using this portable, powerful tech—join hands with me on this journey. Let’s build the next generation of resilient intelligence together.
The Hypothesis Behind This Work
My journey to offline RAG wasn't a straight line. It was an evolution of abstractions that I've shared with you across this series:
The Python Prototype (RAG-1): Starting with raw Python scripts talking to OpenAI's gpt-4o-mini. It worked, but it was tethered to the cloud.
Persistence & Sessions (RAG-2): Moving from scripts to stateful management, implementing PostgreSQL and persistent FAISS stores to prevent "data amnesia."
The Enterprise Shift (RAG-Java): Rebuilding the system using Spring AI . I translated these abstractions from OpenAI to AWS Bedrock, bringing enterprise-grade security, but we were still paying the "Cloud Tax."
The Final Destination (Offline SLM):
"Most real-world AI systems do not need global intelligence. They need localized intelligence that lives close to the data." This is where Small Language Models become interesting—not as weaker versions of LLMs, but as a fundamentally different system component. When paired with strict retrieval boundaries, domain-specific data, and deterministic pipelines, SLMs can deliver usable and reliable intelligence without the overhead of massive models or continuous cloud connectivity.This work is not about “downsizing” AI. It’s about right-sizing it.
The Phase-Wise Evolution: From Script to Standalone Product
Phase 1: The Vision– Defining what we are building and why resilient, localized AI is the future.
Phase 2: The Implementation– Prototyping in Python and scaling with Spring AI & AWS Bedrock abstractions.
Phase 3: The Standalone Demo– Bundling the model, database, and UI into a portable 4GB offline application.

The Technical Transformation
Moving from a multi-billion dollar cloud infrastructure to a local laptop involves more than just a library change. Here is the technical "before and after":
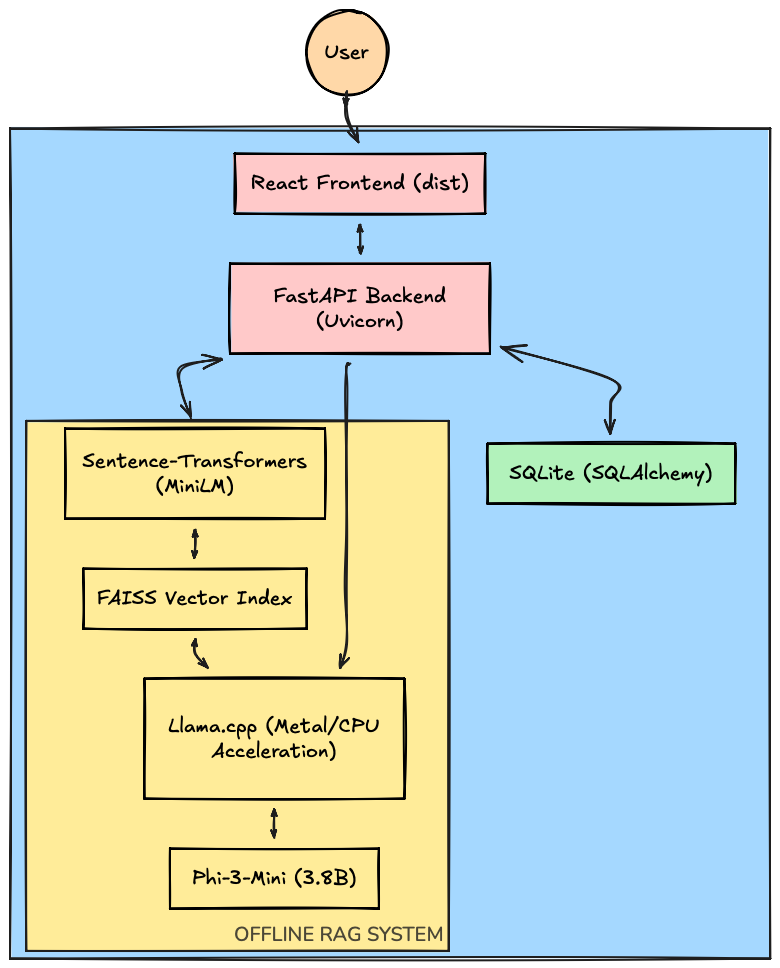
Architectural Overview
AI Engine: AWS Bedrock (Claude/Titan) -> Phi-3-Mini (Local SLM).
Embeddings: AWS Titan -> Sentence-Transformers (all-MiniLM).
Backend: Spring Boot (Java) -> FastAPI(Python).
Database: Managed RDS -> SQLite (SQLAlchemy).
Vector Store: Managed Vector DB -> FAISS (Local Index).
Core RAG Pipeline Transformation
The primary challenge was replicating the heavy cloud computation of AWS Bedrock locally on a standard consumer machine.
A. Local Small Language Model (SLM)
We transitioned the reasoning engine to Phi-3-Mini.
Optimization: We will leverage the GGUF format, which allows the model to run efficiently with low RAM.
Acceleration: we will implement llama-cpp-python with Metal support, allowing the system to utilize the
Apple M4 GPU. This moved token generation which would take minutes on a CPU to near-instantaneous output.
B. Embedding & Indexing
To replace Titan embeddings, we are going to integrate the sentence-transformers library.
Ingestion: We'll Modify the pipeline to extract text locally using PyMuPDF.
Search: Since we no longer had a cloud vector database, we'll implement a local FAISS Index.
Recall Logic: Because FAISS only stores numerical vectors, we'll add a persistence layer where raw text chunks are indexed by their file-system ID in a local chunks.json for rapid context retrieval during the "Augmentation" phase.
Production-Grade Persistence Layer
To ensure the frontend remained 100% functional, we will have to mirror the complex relational schema of the original Java backend using SQLAlchemy and SQLite.
Security Transformation
Since Spring Security was no longer available, we'll built a custom low-dependency security stack.
Closing Position
This work is not an argument against cloud AI. It is an argument against defaulting to the cloud when the problem does not require it.
As AI moves deeper into real systems—classrooms, labs, micro-frontends, and constrained environments—self-contained, localized intelligence will matter more than ever.
This series is my attempt to build that architecture, understand its limits, and document the trade-offs honestly.
🌐 Read more tutorials: https://blog.slayitcoder.in
💼 Connect with me on LinkedIn: https://www.linkedin.com/in/tpushkarsingh